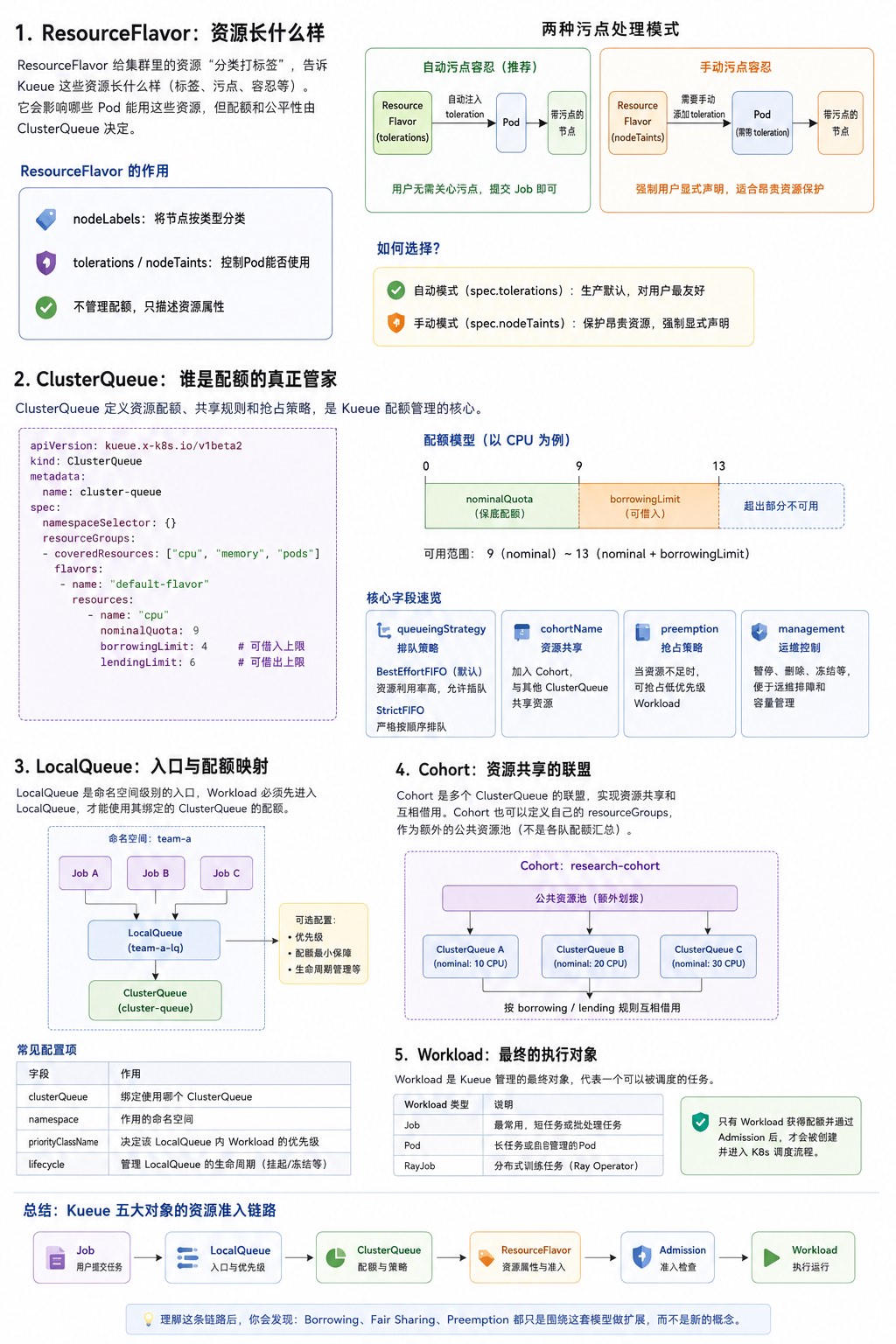
很多人刚接触 Kueue 时最大的困惑,不是 YAML 怎么写,而是看着一堆 CRD:ResourceFlavor、ClusterQueue、LocalQueue、Cohort、Workload,不知道它们之间到底是什么关系。本文不会逐个照着 API 文档介绍字段,而是把这五个对象放到同一条资源准入链路中,一次讲清楚它们各自负责什么、为什么要存在,以及它们之间如何协作。
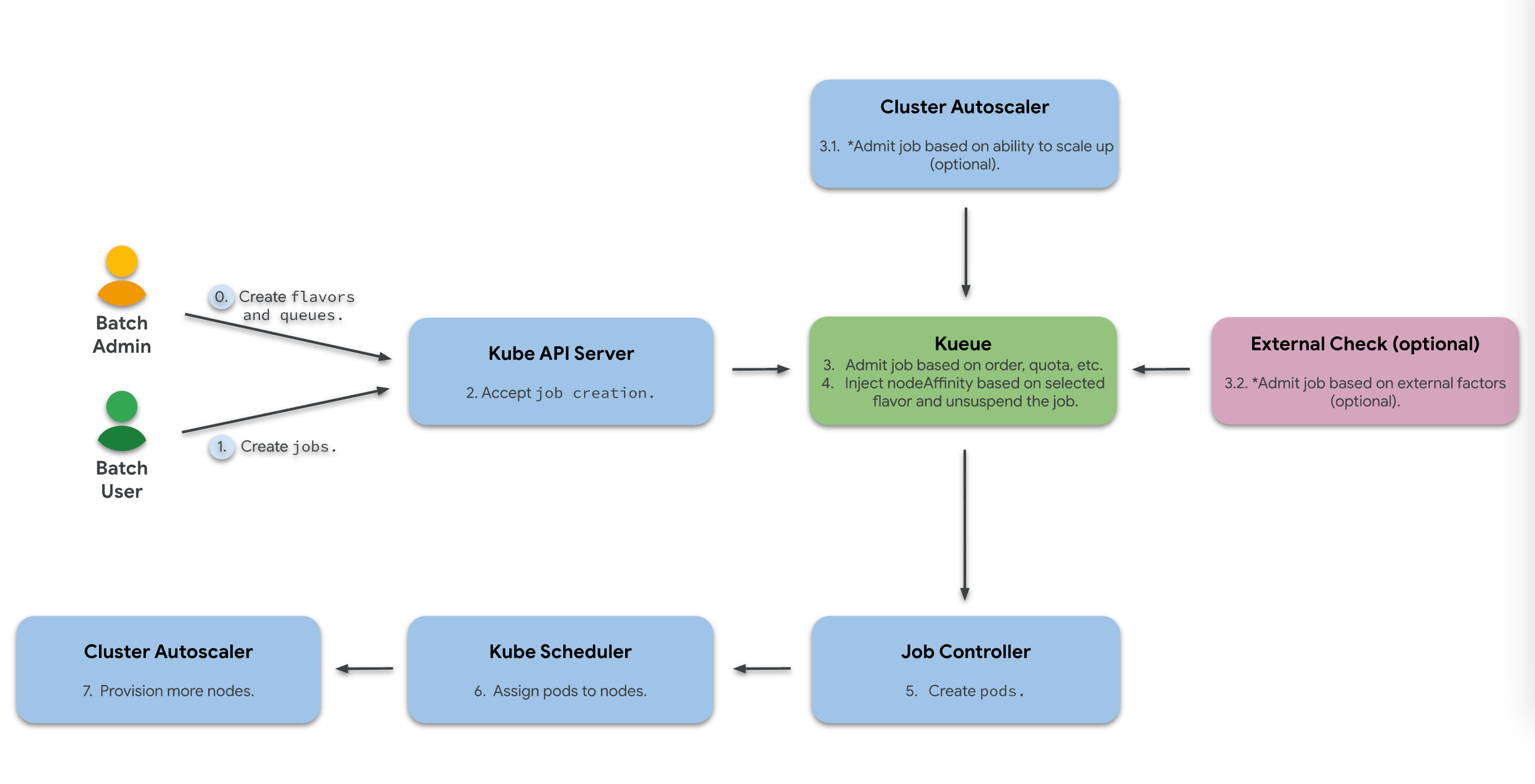
上一篇文章中分析了 Kueue 的完整工作流:
涉及到多个核心对象,下面逐个拆开讲。
1. ResourceFlavor:资源长什么样
Kueue 要管资源,第一步得知道集群里有哪些"种类"的资源。集群里的 CPU、GPU 通常不是同构的:
价格和可用性 :竞价型 vs 按需型虚拟机架构 :x86 vs ARM CPU品牌和型号 :Nvidia A100 vs T4 GPUResourceFlavor 就是干这个的——给资源分个类,贴个标签,后面 ClusterQueue 按这个分类来管配额。
Kueue 在 Admission 阶段,会根据 ClusterQueue 中配置的 Flavor 顺序、Quota 是否满足、Flavor 是否匹配 Pod 等因素,选择一个可用的 ResourceFlavor。
空 Flavor
如果集群资源是同构的,或者不需要为不同资源规格分别管理配额,那直接创建一个不包含任何标签或污点的空 ResourceFlavor 即可:
1
2
3
4
apiVersion : kueue.x-k8s.io/v1beta2
kind : ResourceFlavor
metadata :
name : default-flavor
这类 ResourceFlavor 不承担节点筛选或污点控制的职责,仅作为统一的资源抽象存在,方便后续扩展不同资源类型。
只分类不加污点
1
2
3
4
5
6
7
apiVersion : kueue.x-k8s.io/v1beta2
kind : ResourceFlavor
metadata :
name : "gpu"
spec :
nodeLabels :
instance-type : gpu
新增参数:
spec.nodeLabels这类 Flavor 实现了根据 label 将节点进行分类,算是名副其实。管理员先给节点打上对应 label 即可实现分类:
1
2
root@lixd-dev-4:~# kubectl label node lixd-dev-4 instance-type= gpu
node/lixd-dev-4 labeled
但也只是简单做了分类,不是该 Flavor 中的 Job 也能手动调度到这些 GPU 节点。比较推荐的做法是给节点再打上污点,这样就不是随便能调度上去了:
1
kubectl taint node xxx nvidia.com/gpu= true:NoSchedule
节点打上污点后,Flavor 中的 Job 也不能调度了。Kueue 提供了两种模式来解决这个问题:
自动容忍模式 :将污点容忍信息写到 ResourceFlavor,Kueue 自动给使用该 Flavor 的 Pod 加上容忍手动容忍模式 :将污点信息写到 ResourceFlavor,Kueue 做匹配拦截,只允许带了对应容忍的 Pod 使用该 Flavor带污点
自动污点容忍调度
1
2
3
4
5
6
7
8
9
10
11
apiVersion : kueue.x-k8s.io/v1beta2
kind : ResourceFlavor
metadata :
name : "spot"
spec :
nodeLabels :
instance-type : spot
tolerations :
- key : "spot-taint" # 节点上已有污点的 key
operator : "Exists"
effect : "NoSchedule" # 支持 NoSchedule 和 NoExecute
新增参数:
spec.tolerations.spec.template.spec.tolerations,确保 Pod 能容忍节点污点从而正常调度。手动污点容忍
1
2
3
4
5
6
7
8
9
10
11
apiVersion : kueue.x-k8s.io/v1beta2
kind : ResourceFlavor
metadata :
name : "spot"
spec :
nodeLabels :
instance-type : spot
nodeTaints :
- effect : NoSchedule # 只支持 NoSchedule 和 NoExecute,PreferNoSchedule 会被忽略
key : spot
value : "true"
新增参数:
spec.nodeTaints不会 自动注入容忍度,Pod 必须自己带对应 toleration 才能通过准入、拿到配额。用户提交 Job 时必须自己带上 toleration,否则 Kueue 不批配额:
1
2
3
4
5
6
7
spec :
template :
spec :
tolerations :
- key : spot
operator : Exists
effect : NoSchedule
注意 :spec.nodeTaints 通常应与节点上的真实污点保持一致。否则可能出现 Pod 过了 Kueue 准入、拿到配额,但 K8s 调度器发现节点有真污点而 Pod 没对应 toleration,最终调度失败——白白占了配额。本质就是把调度层面的拦截提前到 Kueue 准入层面 。
两种模式怎么选
自动模式(spec.tolerations) 手动模式(spec.nodeTaints) 谁给 Pod 加 toleration Kueue 自动注入 用户自己写 用户需要关心节点污点吗 不需要,提交 Job 就行 必须自己写 toleration 用在哪 生产默认,对用户最友好 保护昂贵资源,强制用户显式声明
选型建议:优先用自动模式 ;只有当你需要强制用户显式声明才能使用某种昂贵资源时,才用手动模式。
一句话记住:ResourceFlavor 定义资源的属性(标签、污点、容忍等),真正决定资源配额和公平性的仍然是 ClusterQueue。
2. ClusterQueue:谁是配额的真正管家
如果 ResourceFlavor 是给资源分类,那真正决定谁能用、用多少的是谁?答案就是 ClusterQueue。它才是 Kueue 配额管理的核心,定义了使用上限和公平共享规则。
基础用法
一个基础的 ClusterQueue 示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : "cluster-queue"
spec :
namespaceSelector : {} # 匹配所有命名空间。
resourceGroups :
- coveredResources : [ "cpu" , "memory" , "pods" ]
flavors :
- name : "default-flavor"
resources :
- name : "cpu"
nominalQuota : 9
- name : "memory"
nominalQuota : 36Gi
- name : "pods"
nominalQuota : 5
字段解析:
spec.namespaceSelectorresourceGroupscoveredResourcesflavorsnameresourcesnominalQuotaborrowingLimitlendingLimit以 cpu 为例,基于上面三个配额字段,你可以使用的范围是 nominalQuota ~ (nominalQuota + borrowingLimit)。
高级用法
在基础配置之上,ClusterQueue 还支持以下进阶字段,按用途分组:
调度顺序:排队策略
1
2
spec :
queueingStrategy : BestEffortFIFO
BestEffortFIFO(默认)StrictFIFO资源共享:加入 Cohort
1
2
spec :
cohortName : research-cohort
cohortName抢占相关
当 ClusterQueue 或其 Cohort 中没有足够的配额时,新进入的 Workload 可以触发预抢占,挤掉低优先级的 Workload。涉及两个配置项:
预抢占策略
1
2
3
4
5
6
7
spec :
preemption :
reclaimWithinCohort : Any # 可抢占 Cohort 中超过名义配额的 Workload
borrowWithinCohort :
policy : LowerPriority # 借用时只抢占低优先级(不能与 Fair Sharing 一同使用)
maxPriorityThreshold : 100 # 且仅抢占优先级 ≤ 100 的 Workload
withinClusterQueue : LowerPriority # 同队列内,低优先级让路给高优先级
withinClusterQueueNever(默认)不抢占;LowerPriority 仅抢占低优先级;LowerOrNewerEqualPriority 抢占低优先级或同优先级的。reclaimWithinCohortNever(默认)不抢占;LowerPriority 仅抢占低优先级;Any 可抢占任意优先级。borrowWithinCohortNever(默认)不触发;LowerPriority 仅抢占 Cohort 中低优先级的 Workload(需同时启用 reclaimWithinCohort)。注意:只能配置经典抢占,不能与 Fair Sharing 一同使用 。优先抢占还是借用
当 ClusterQueue 有多个 flavor 时,Kueue 按顺序尝试。当当前 flavor 配额用完时,你可以影响 Kueue 的行为:
whenCanBorrowMayStopSearch(默认):借了就停,不再试下一个;TryNextFlavor:不借,先试下一个 flavor。whenCanPreemptTryNextFlavor(默认):先试下一个 flavor;MayStopSearch:不试了,直接抢占。1
2
3
4
spec :
flavorFungibility :
whenCanBorrow : TryNextFlavor
whenCanPreempt : MayStopSearch
运维控制:停止策略
控制队列的运行状态,ClusterQueue 和 LocalQueue 都支持。
None(默认)HoldHoldAndDrain维护完恢复为 None 或直接删掉这个字段即可。这是运维操作,不是常态配置。
1
2
spec :
stopPolicy : Hold
把上面的都放在一起
一个包含所有字段的完整 ClusterQueue:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : ai-team-cq
spec :
# 1. 加入 Cohort,允许和其他 ClusterQueue 共享资源
cohortName : research-cohort
# 2. 排队策略
queueingStrategy : BestEffortFIFO # 默认。StrictFIFO 会阻塞
# 3. 命名空间选择器(谁能用这个 ClusterQueue)
namespaceSelector :
matchLabels :
team : ai
# 4. 抢占策略
preemption :
reclaimWithinCohort : Any # 可抢占 Cohort 中超过名义配额的 Workload
borrowWithinCohort :
policy : LowerPriority # 借用时只抢占低优先级(不能与 Fair Sharing 一同使用)
maxPriorityThreshold : 100 # 且仅抢占优先级 ≤ 100 的 Workload
withinClusterQueue : LowerPriority # 同队列内,低优先级让路给高优先级
# 5. 配置是优先抢占还是借用
flavorFungibility :
whenCanBorrow : TryNextFlavor
whenCanPreempt : MayStopSearch
# 6. 停止策略
# stopPolicy: Hold
# 7. 资源组定义
resourceGroups :
- coveredResources : [ "cpu" , "memory" ] # 第一组:计算资源
flavors :
- name : default-flavor
resources :
- name : cpu
nominalQuota : 16 # 保底配额
borrowingLimit : 8 # 最多能从 Cohort 借多少
lendingLimit : 8 # 最多允许别人借多少
- name : memory
nominalQuota : 64Gi
borrowingLimit : 32Gi
lendingLimit : 32Gi
- coveredResources : [ "nvidia.com/gpu" ] # 第二组:GPU 资源
flavors :
- name : a100
resources :
- name : nvidia.com/gpu
nominalQuota : 4
borrowingLimit : 2
- name : t4
resources :
- name : nvidia.com/gpu
nominalQuota : 8
一句话记住:ClusterQueue 才是真正管配额和公平性的地方。 第一次看会和 LocalQueue 搞混,其实记住一句就够了——ClusterQueue 管资源,LocalQueue 管用户。
3. LocalQueue:用户怎么进队列
ClusterQueue 是集群级别的,但用户不能直接往里塞 Job。中间还需要一层 LocalQueue——它是一个命名空间对象,指向一个 ClusterQueue,作为用户提交 Job 的入口。
1
2
3
4
5
6
7
apiVersion : kueue.x-k8s.io/v1beta2
kind : LocalQueue
metadata :
namespace : team-a
name : team-a-queue
spec :
clusterQueue : cluster-queue
注意:kubectl get queues 是 kubectl get localqueues 的别名,更方便日常使用。
LocalQueue vs ClusterQueue
维度 LocalQueue ClusterQueue 作用域 命名空间 集群 谁创建 团队自己 批处理管理员 职责 将同一租户的工作负载分组,指向一个 ClusterQueue 管理资源池的配额和公平共享规则 一对一? 多个 LocalQueue 可以指向同一个 ClusterQueue —
1
2
3
4
5
命名空间 team-a:
LocalQueue: training-queue ──┐
LocalQueue: inference-queue ──┼──→ ClusterQueue: ai-team-cq
命名空间 team-b: │
LocalQueue: batch-queue ──────┘
一句话记住:LocalQueue 就是 Namespace 访问 ClusterQueue 的入口。 它不管配额,只管"我这个 namespace 的 Job 往哪个 ClusterQueue 送"。
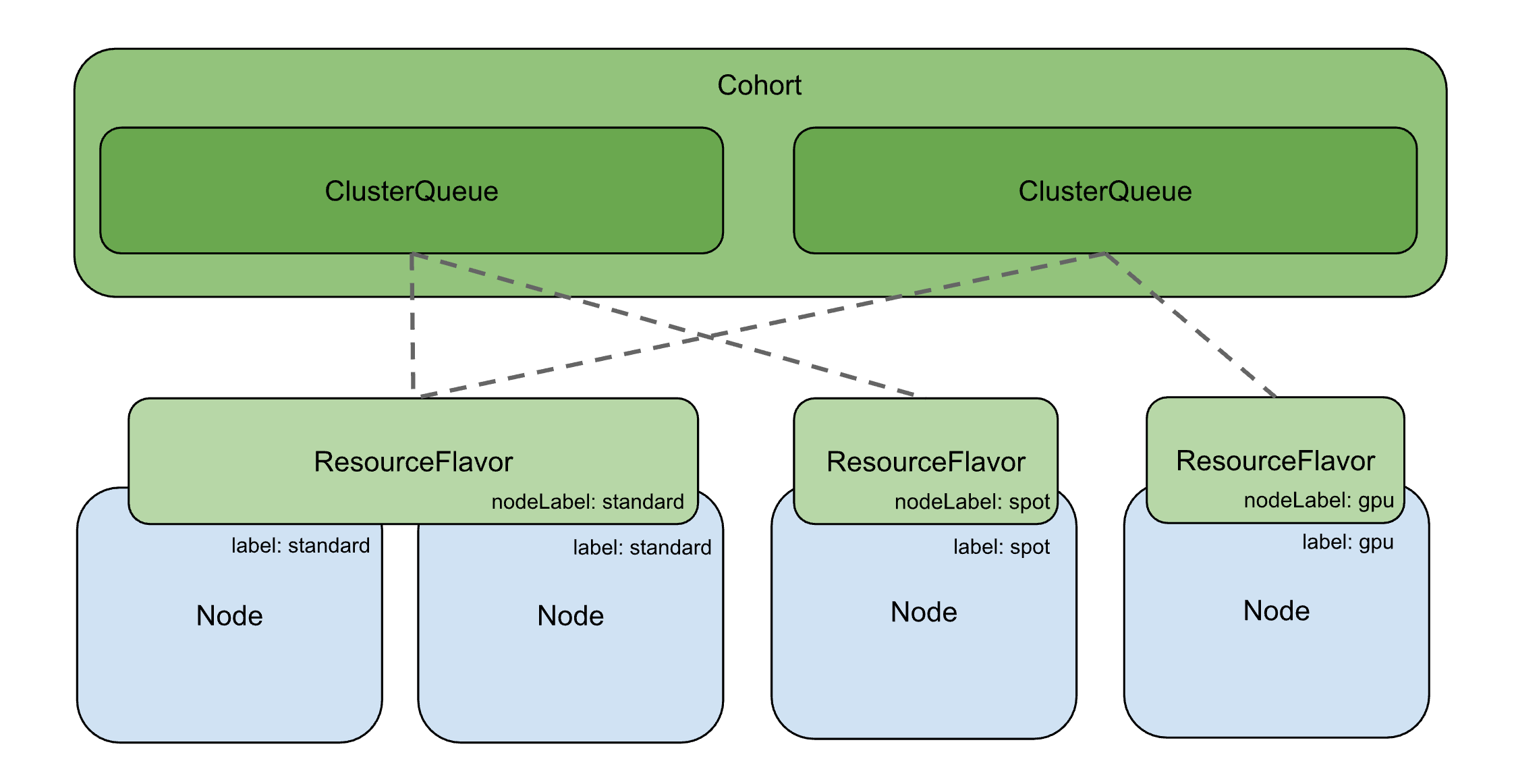
4. Cohort:队列之间怎么借资源
如果每个 ClusterQueue 只能用自己的保底配额,那 team-a 闲着 3 核、team-b 想多跑 1 核也借不到,资源就浪费了。Cohort 就是解决这个的——可以理解成一个"资源共享联盟",加进同一个 Cohort 的 ClusterQueue 可以互相借配额。
第一次看 Cohort 我也没太理解。后来发现,它本身还能定义 resourceGroups(共享配额池),这些资源是管理员额外划拨给整个联盟的公共池,而不是把各个 ClusterQueue 的 nominalQuota 自动汇总得到的。
基本用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 创建 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : Cohort
metadata :
name : hello-cohort
spec :
resourceGroups :
- coveredResources : [ "cpu" ]
flavors :
- name : default-flavor
resources :
- name : cpu
nominalQuota : 12 # Cohort 级别的共享配额(额外资源)
---
# ClusterQueue A 加入 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : team-a-cq
spec :
cohortName : hello-cohort
resourceGroups :
- coveredResources : [ "cpu" ]
flavors :
- name : default-flavor
resources :
- name : cpu
nominalQuota : 4
borrowingLimit : 4 # 最多借 4 核
lendingLimit : 2 # 最多出借 2 核
---
# ClusterQueue B 也加入同一个 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : team-b-cq
spec :
cohortName : hello-cohort
resourceGroups :
- coveredResources : [ "cpu" ]
flavors :
- name : default-flavor
resources :
- name : cpu
nominalQuota : 4
borrowingLimit : 4
lendingLimit : 2
上面的配置意味着:
两个队列各有 4 核保底,Cohort 自己配置的一组共享配额 12 核。(总计可用 20 核) 空闲时可以互相借用 如果 ClusterQueue 想从 Cohort 借用资源,它必须 为该资源和 Flavor 定义 nominalQuota(即使值为 0) 分层 Cohort(Hierarchical Cohorts)
Cohort 可以组织成树形结构(CohortTree),适合大型组织:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 根 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : Cohort
metadata :
name : root-cohort
---
# AI 部门 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : Cohort
metadata :
name : ai-dept
spec :
parentName : root-cohort # 父节点
fairSharing :
weight : "0.75"
---
# 大数据部门 Cohort
apiVersion : kueue.x-k8s.io/v1beta2
kind : Cohort
metadata :
name : bigdata-dept
spec :
parentName : root-cohort # 父节点
fairSharing :
weight : "0.25"
1
2
3
4
5
6
7
root-cohort(总资源池)
├── ai-dept(权重 0.75 → 趋向使用 75% 公共资源)
│ ├── team-a-cq
│ └── team-b-cq
└── bigdata-dept(权重 0.25 → 趋向使用 25% 公共资源)
├── spark-cq
└── flink-cq
同一个 CohortTree 中的 ClusterQueue 可以使用其中的资源,遵循为 Cohort 和 ClusterQueue 指定的借用和借出限制。
一句话记住:Cohort 让多个 ClusterQueue 可以互相借资源。
5. Workload:Kueue 真正在调度什么
前面四个都是"配置",那 Kueue 真正调度、准入的对象是什么?是 Workload——一个要运行至完成的应用,由一个或多个 Pod 组成。Kueue 的 Admission、Quota Accounting、Preemption 全是围绕它展开的。
通常你不需要手动创建 Workload ,Kueue 会为每个 Job 自动创建。但理解它的结构有助于排查问题。
关键字段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
apiVersion : kueue.x-k8s.io/v1beta2
kind : Workload
metadata :
name : sample-job
namespace : team-a
spec :
active : true # 设为 false 可停止 Workload(已运行的会被驱逐且不重新排队)
queueName : team-a-queue # 指向 LocalQueue
podSets : # Pod 组定义(Kueue 从 Job 自动提取)
- name : main
count : 3 # Pod 数量
template :
spec :
containers :
- name : container
image : registry.k8s.io/e2e-test-images/agnhost:latest
resources :
requests :
cpu : "1"
memory : 200Mi
maximumExecutionTimeSeconds : 3600 # Workload 处于 Admitted 状态超过此秒数后自动停用
优先级
Workload 的优先级影响准入顺序,有两种设置方式:
Pod 优先级 :对于 batch/v1.Job,Kueue 根据 Job 的 Pod 模板的 Pod 优先级设置 Workload 的优先级WorkloadPriorityClass :独立管理工作负载的排队和抢占优先级,与 Pod 调度优先级分离1
2
3
4
5
6
apiVersion : kueue.x-k8s.io/v1beta2
kind : WorkloadPriorityClass
metadata :
name : high-priority
value : 1000
description : "高优先级训练任务"
使用方式:在 Job 的 label 中指定:
1
2
3
metadata :
labels :
kueue.x-k8s.io/priority-class : high-priority
资源请求计算
Kueue 将 Workload 的总资源使用量计算为每个 podSet 资源请求的总和:
podSet 的资源使用量 = Pod 规格的资源请求 × count
Kueue 会根据 Limit Ranges 和 Runtime Class Overhead 调整资源使用量。
一句话记住:Workload 才是 Kueue 真正调度和准入的对象 ,前面四个对象都是给它配规则的。
6. Demo:串联五大核心对象
理论讲完了,下面用一个 demo 把五大核心对象串起来,验证配额管控和 Cohort 借用能力。环境是一个单节点 K8s 集群(8 核 CPU)+ Kueue v0.18.1。
1
2
3
4
5
Cohort(team-ab)
├── team-a-cq(保底 4 核,最多借到 6 核)
│ └── team-a-queue
└── team-b-cq(保底 2 核,最多借到 5 核)
└── team-b-queue
Step 1:给节点打 label 和 taint
1
2
3
4
5
# 打 label,标记节点类型
kubectl label node lixd-dev-4 node-type= cpu
# 加 taint,防止没有容忍的 Pod 调度上来
kubectl taint node lixd-dev-4 dedicated = team:NoSchedule
Step 2:创建 ResourceFlavor(tolerations 自动模式)
1
2
3
4
5
6
7
8
9
10
11
apiVersion : kueue.x-k8s.io/v1beta2
kind : ResourceFlavor
metadata :
name : cpu-flavor
spec :
nodeLabels :
node-type : cpu # 匹配节点
tolerations : # Kueue 自动注入 Pod,容忍节点污点
- key : dedicated
operator : Exists
effect : NoSchedule
Step 3:创建 Cohort + 两个 ClusterQueue + 两个 LocalQueue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# Cohort:让两个队列共享配额
apiVersion : kueue.x-k8s.io/v1beta2
kind : Cohort
metadata :
name : team-ab
---
# team-a:保底 4 核,最多借到 6 核
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : team-a-cq
spec :
cohortName : team-ab
namespaceSelector : {}
resourceGroups :
- coveredResources : [ "cpu" , "pods" ]
flavors :
- name : cpu-flavor
resources :
- name : cpu
nominalQuota : 4
borrowingLimit : 2
- name : pods
nominalQuota : 3
---
# team-b:保底 2 核,最多借到 5 核
apiVersion : kueue.x-k8s.io/v1beta2
kind : ClusterQueue
metadata :
name : team-b-cq
spec :
cohortName : team-ab
namespaceSelector : {}
resourceGroups :
- coveredResources : [ "cpu" , "pods" ]
flavors :
- name : cpu-flavor
resources :
- name : cpu
nominalQuota : 2
borrowingLimit : 3
- name : pods
nominalQuota : 3
---
apiVersion : kueue.x-k8s.io/v1beta2
kind : LocalQueue
metadata :
namespace : default
name : team-a-queue
spec :
clusterQueue : team-a-cq
---
apiVersion : kueue.x-k8s.io/v1beta2
kind : LocalQueue
metadata :
namespace : default
name : team-b-queue
spec :
clusterQueue : team-b-cq
Step 4:提交 Job A(team-a,3 核,保底内)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion : batch/v1
kind : Job
metadata :
name : job-a
labels :
kueue.x-k8s.io/queue-name : team-a-queue
spec :
template :
spec :
containers :
- name : sleep
image : busybox
command : [ 'sleep' , '30' ]
resources :
requests :
cpu : '3'
restartPolicy : Never
30 秒后 Job A 跑完,验证 Kueue 自动注入了 toleration 和 nodeSelector:
1
2
3
4
5
$ kubectl get pod job-a-<pod-suffix> -o jsonpath = '{.spec.tolerations[0]}'
{ "effect" :"NoSchedule" ,"key" :"dedicated" ,"operator" :"Exists" } # ← 自动注入的
$ kubectl get pod job-a-<pod-suffix> -o jsonpath = '{.spec.nodeSelector}'
{ "node-type" :"cpu" } # ← 自动注入的
Step 5:提交 Job B(team-b,3 核,需要借用)
team-b 保底只有 2 核,要 3 核需要从 team-a 借 1 核空闲配额(此时 Job A 还在跑,用了 3 核,team-a 空闲 1 核)。
此时提交 JobB:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion : batch/v1
kind : Job
metadata :
name : job-b
labels :
kueue.x-k8s.io/queue-name : team-b-queue
spec :
template :
spec :
containers :
- name : sleep
image : busybox
command : [ 'sleep' , '30' ]
resources :
requests :
cpu : '3'
restartPolicy : Never
借用过程:team-a 保底 4 核用了 3 核,空闲 1 核 → team-b 保底 2 核不够(要 3 核)→ 从 team-a 借了 1 核 → 准入成功。
30 秒后 Job B 跑完,team-b 的 3 核配额归还。等 Job A 也跑完后 ,整个 Cohort 就空了:team-a 保底 4 核全空闲,team-b 保底 2 核全空闲,总共 6 核可借。
Step 6:提交 Job D(team-b,5 核,测试 borrowingLimit 上限)
Job A、Job B 都已跑完,配额全部归还。现在 team-b 最多能用保底 2 + 借 3 = 5 核(team-a 空闲 4 核,足够借)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion : batch/v1
kind : Job
metadata :
name : job-d
labels :
kueue.x-k8s.io/queue-name : team-b-queue
spec :
template :
spec :
containers :
- name : sleep
image : busybox
command : [ 'sleep' , '600' ]
resources :
requests :
cpu : '5'
restartPolicy : Never
结果:
1
2
3
$ kubectl get workloads
NAME QUEUE ADMITTED
job-job-d-fd3f3 team-b-queue True # 保底2+借3=5,刚好到上限,准入
Step 7:提交 Job E(team-b 再多 1 核,超过 borrowingLimit)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
apiVersion : batch/v1
kind : Job
metadata :
name : job-e
labels :
kueue.x-k8s.io/queue-name : team-b-queue
spec :
template :
spec :
containers :
- name : sleep
image : busybox
command : [ 'sleep' , '120' ]
resources :
requests :
cpu : '1'
restartPolicy : Never
结果:
1
2
3
4
5
6
7
8
$ kubectl get workloads
NAME QUEUE ADMITTED
job-job-d-fd3f3 team-b-queue True # 5核已用满
job-job-e-918d8 team-b-queue False # 再多 1 核,Pending
$ kubectl get workload job-job-e-918d8 -o jsonpath = '{.status.conditions[0].message}'
insufficient unused quota for cpu in flavor cpu-flavor, 1 more needed
# team-b 最多 5 核,Job D 已用 5 核,没有余量了
小结
Job 团队 请求 CPU 保底 借用 结果 Job A team-a 3 核 4 核 0 ✅ 准入 Job B team-b 3 核 2 核 借 1 核 ✅ 准入 Job D team-b 5 核 2 核 借 3 核 ✅ 准入(到 borrowingLimit 上限) Job E team-b 1 核 已满 无法借 ❌ Pending
5 个核心对象在这里全部串联起来了。
7. 小结
Kueue 的核心,其实不是“调度算法”,而是围绕 Workload 的准入与资源分配模型。
五个对象分别扮演了不同角色,但可以用一句话快速串起来:
ResourceFlavor :定义“资源长什么样”(节点/污点/标签)ClusterQueue :定义“资源怎么分、给谁多少”LocalQueue :定义“哪个命名空间用哪个资源池”Cohort :定义“多个队列之间如何共享资源”Workload :真正被调度和准入的执行单元第一次接触 Kueue 时,很容易把这些对象看成彼此独立的 CRD,但实际上它们共同组成了一条完整的资源准入链路:
1
Job → LocalQueue → ClusterQueue → ResourceFlavor → Admission → Workload
理解了这条链路,再去看 Borrowing、Fair Sharing、Preemption 等高级能力,就会发现它们都只是围绕这套模型做扩展,而不是新的概念。