AI 时代,你的 HPA 可能已经失灵了

不知道你们有没有发现,进入 AI 时代之后,传统微服务那套 HPA 好像突然不好使了。
CPU 20%,内存 30%,监控面板一片岁月静好,但你的 AI 推理服务已经在排队了。HPA 看了一眼指标,嗯,一切正常,不用扩。
这不是 HPA 的 bug,是它背后那套「资源使用率等于负载压力」的逻辑,在 AI 推理场景下从根上就不成立。问题不在调参,在于观测信号本身就是失真的。
今天就来聊聊这件事的来龙去脉,以及目前我们认为最合理的解法,KEDA。
1. HPA 在 AI 场景下到底错在哪
先说清楚 HPA 的底层逻辑。
HPA(Horizontal Pod Autoscaler)的设计假设是,资源使用率跟负载压力成正比。CPU 高了说明忙,内存高了说明扛不住,扩就完事了。对传统 Web 服务来说,这个假设基本成立,请求来了 CPU 就涨,请求走了 CPU 就降,很线性。
但 AI 推理服务把这个假设的每一个环节都打破了。以图片生成服务为例。

第一个问题,GPU 显存是常驻的
图片生成服务启动的时候,第一件事就是把模型权重加载到 GPU 显存里。比如 Stable Diffusion SDXL 这种级别的模型,光权重就要好几个 GB,加载完之后,这些显存就一直占着,不管你有没有请求,它都是满的。
所以你如果用 GPU 显存使用率做 HPA 指标,服务刚启动就已经「满」了。HPA 会觉得你一直需要扩容,即使压根没有任何请求在处理。
第二个问题,GPU 计算使用率跟请求量不成正比
生成一张图片,一般要迭代几十上百步,整个过程可能就要几秒到几十秒。在这个过程中,GPU 使用率直接飙到 90% 甚至 100%。
问题在于,一个请求就能把 GPU 跑满。1 个请求和 10 个请求,在 GPU 使用率上看起来差不多,都是满载。 HPA 那套「采样窗口取平均值再做判断」的逻辑,放到这里完全没意义,因为不管采多少秒,看到的都是满载。
更离谱的是,你按 GPU 使用率做 HPA,一个请求过来就触发扩容,扩出来的 Pod 加载模型要 30 秒到 2 分钟,等它准备好,原来那个请求早就处理完了。
你可能会想,那 CPU 呢?内存呢?
第三个问题,CPU 和内存指标跟 GPU 负载无关
推理服务的 CPU 主要做些预处理和调度,内存主要是模型权重的 CPU 侧缓存。0 个请求和 10 个请求的 CPU/内存使用,差别可能就是几个百分点。
所以,三个问题,三条路,全堵死了。HPA 最依赖的两个指标,在 AI 推理场景下,全部失真。
| 指标 | 传统 Web 服务 | AI 推理服务 |
|---|---|---|
| GPU 显存 | 随负载动态变化 | 模型加载后常驻满载 |
| GPU 计算使用率 | 与请求量正相关 | 一个请求就能拉满,无法反映积压程度 |
| CPU 使用率 | 与请求量正相关 | 仅做预处理,变化极小 |
| 内存使用率 | 与请求量正相关 | 主要是模型缓存,基本不变 |
| HPA 扩容效果 | 准确 | 失真 |
这就是为什么 HPA 在 AI 场景下不是扩错了,就是扩晚了,要么干脆就不扩。它的设计假设被 AI 服务或者 GPU 的工作模式彻底打碎了。
那怎么办?
2. 别看机器忙不忙,看活多不多
HPA 之所以在 AI 场景下失灵,是因为它在看「机器忙不忙」。但 AI 推理的真正压力不在机器指标上,在「有多少活等着干」。
那「活」在哪?
- 可能是消息队列里积压的消息
- 可能是数据库里状态为 pending 的任务记录
- 可能是对象存储里等着处理的文件
- 也可能是外部系统通过 webhook 推过来的请求
形式不同本质一样,都是「有多少事还没干」。
对 AI 推理来说,最常见的载体是消息队列。图片生成、视频生成这些请求动辄几秒、几十秒甚至几分钟的,一般都会走异步处理。用户请求先进 MQ 排队,Worker 从队列里消费。队列里积压了多少消息,就是有多少待处理的推理请求。
这就是最真实的扩容信号。不根据指标看 GPU 忙不忙,直接看系统里有多少活没干完。
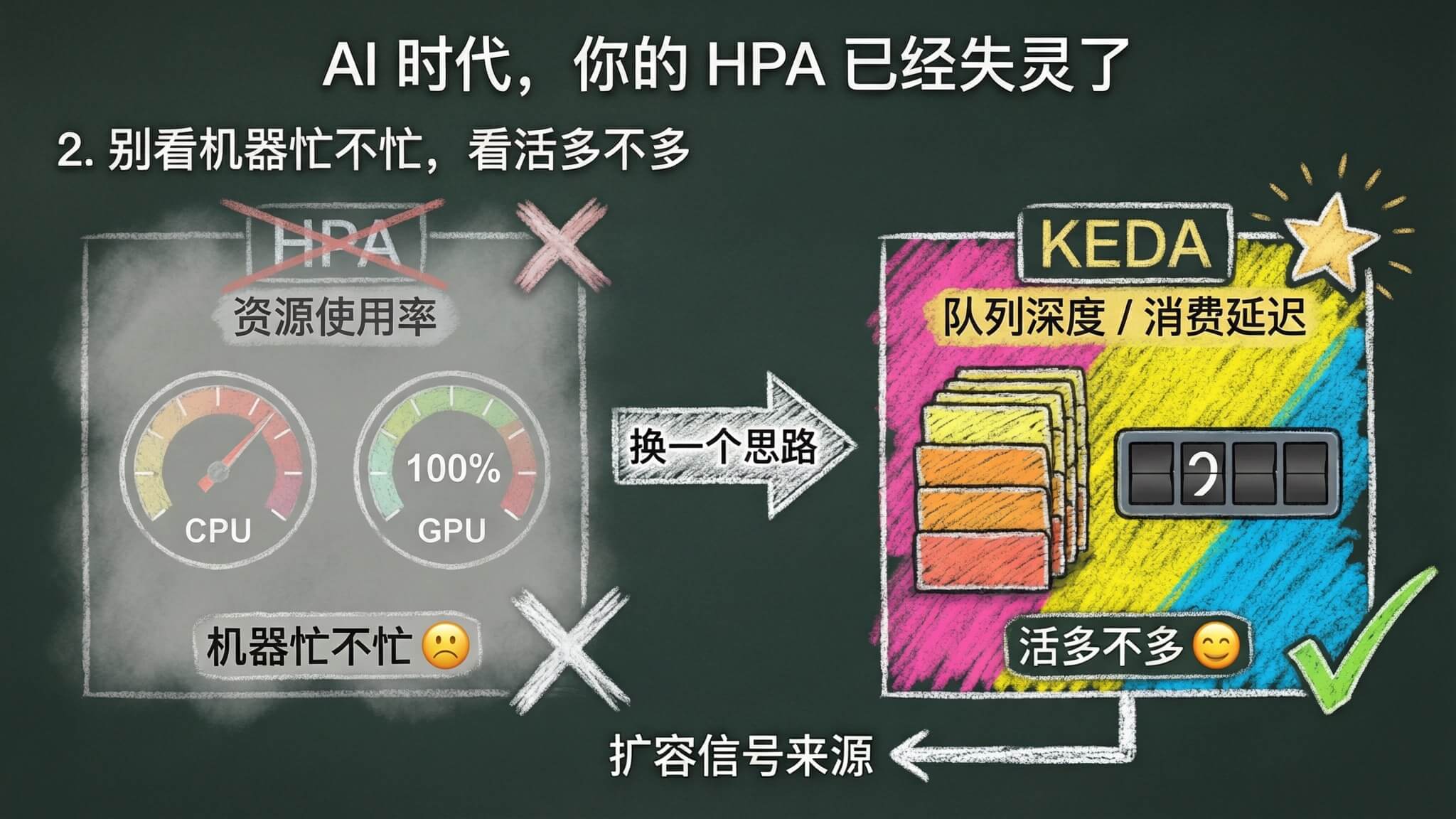
KEDA 干的就是这件事。
KEDA 全称 Kubernetes Event-driven Autoscaling,核心思路特别简单,根据外部事件源的状态来决定扩缩容,而不是看 Pod 的资源使用率。消息队列里有积压就扩,没消息就缩,就是这么直接。
用一张表对比一下 HPA 和 KEDA 的核心差异。
| 对比维度 | HPA | KEDA |
|---|---|---|
| 扩容信号来源 | Pod 资源使用率(CPU/内存/自定义指标) | 外部事件源(队列深度、消费延迟等) |
| 信号本质 | 机器侧,看「忙不忙」 | 需求侧,看「活多不多」 |
| Scale to Zero | 不支持,minReplicaCount 最低为 1 | 原生支持 |
| 外部指标接入复杂度 | 需要 Prometheus Adapter + ServiceMonitor + 自定义指标 + HPA 规则 | 一个 ScaledObject CRD 搞定 |
| 适合场景 | 传统 Web 服务,资源使用率与负载线性相关 | 异步处理,负载压力体现在队列积压 |
KEDA 支持 60 多种 Scaler,包括 Kafka、RabbitMQ、Redis、Prometheus、Cron 等,每个 Scaler 对接一种外部事件源,直接读取事件源的指标来决定扩缩容。
其中几个关键差异值得说一下。
可以缩到零。 没有请求的时候直接把 Pod 数量缩到 0,有请求来了再拉起来。对 GPU 这种昂贵资源来说,不用的时候就不占是最优的。
扩容信号直接来自需求侧。 不再绕一圈去猜 GPU 忙不忙,直接看队列深度、消费延迟这些业务强相关指标。
配置更简单。 用 HPA 接外部指标,你得部署 Prometheus Adapter、写 ServiceMonitor、配自定义指标、再写 HPA 规则,一整套流水线。KEDA 就一个 ScaledObject CRD,声明一下触发器类型和参数就搞定了。
下面用一个 demo 把整个流程跑一遍,让大家有一个大致的印象。
3. 实战,用 RabbitMQ 驱动 KEDA 扩缩容
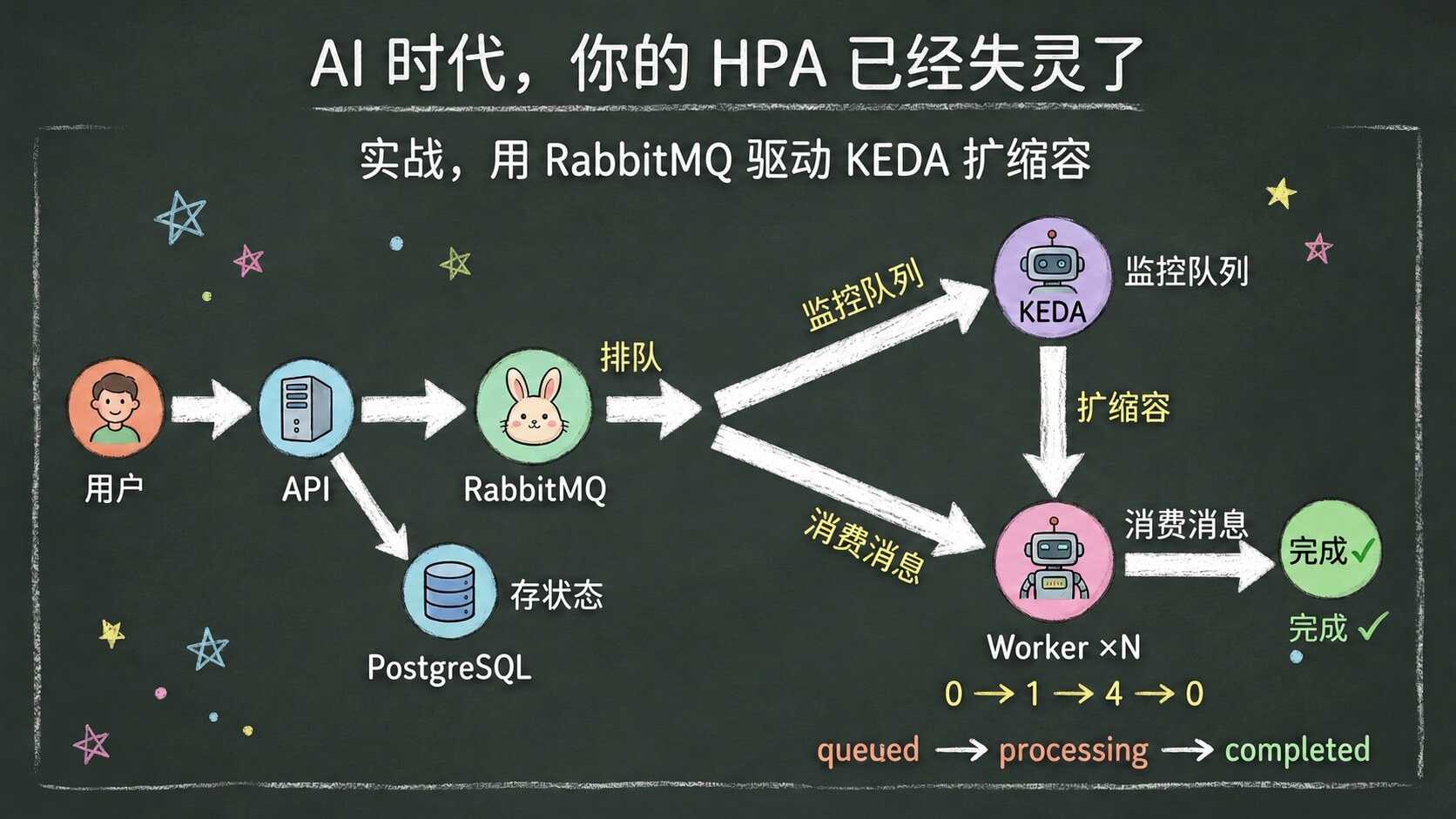
我们搞了一个 demo 项目,模拟一个典型的 AI 图片生成服务架构,演示完整的流程。 整体架构如下。
- 1)用户提交「生成一张猫的图片」这样的请求
- 2)API 接收后把任务写入 DB 做状态追踪,同时把 task ID 发到 RabbitMQ
- 3)Worker 从队列消费任务,没有真正跑模型服务,而是 sleep 一段模拟 Stable Diffusion 那种几秒到几十秒的推理延迟,然后把任务标记为完成。
- 4)KEDA 监控 RabbitMQ 队列深度,队列有积压就自动扩 Worker,没消息就缩到零。
为什么选图片生成? 因为图片/视频生成是 KEDA 扩容最典型的 AI 场景。这类请求处理时间长,没法像 ChatGPT 那样实时返回,必须走异步架构。用户提交请求后拿到一个 task ID,过几秒再来查结果。这个架构和真实 Stable Diffusion API、ComfyUI 工作流、甚至 Sora 类视频生成服务的后端,逻辑是一样的。
为什么加了 DB? 因为真实的图片生成服务,用户提交请求后需要能查到任务状态,从 queued 到 processing 到 completed,这个生命周期需要持久化存储。MQ 只负责通知 Worker 有新任务,不负责存状态。
真实的 AI 推理当然不会用 sleep,这里用 sleep 只是为了模拟推理耗时,让你不用 GPU 也能跑通完整的 KEDA 扩缩容流程。架构、队列、扩缩容逻辑,跟生产环境一模一样。
代码和全部部署文件在 GitHub,keda-ai-queue-demo,下面逐个讲关键部分。
3.1 准备工作
需要一个跑着 Kubernetes 的集群,并且装好 KEDA。
| |
装完确认一下。
| |
应该能看到 keda-operator 和 keda-operator-metrics-apiserver 两个 Pod 在运行。
3.2 部署
克隆项目,直接 apply 即可,镜像已推送到 Docker Hub。
| |
一行搞定部署,PostgreSQL、RabbitMQ、API、Worker、KEDA ScaledObject 全部拉起来。
| |
确认 Pod 状态。
| |
应该看到 PostgreSQL、RabbitMQ、API 三个 Pod 在运行,Worker 的 replicas 是 0,因为队列里还没消息,KEDA 不会给它扩容。
3.3 核心配置,KEDA ScaledObject
整个事件驱动扩缩容的配置就这一个 YAML。
| |
逐个解释一下。
scaleTargetRef: worker,KEDA 只管 Worker 这个 Deployment,API 和 PostgreSQL 跟 KEDA 无关。
pollingInterval: 5,每 5 秒检查一次队列状态。AI 推理服务对响应时间敏感,轮询间隔可以设短一点,默认是 30 秒。
cooldownPeriod: 60,队列清空后 60 秒才缩容。demo 里设短一点方便观察,实际使用建议设 300 秒以上,避免模型反复加载。
minReplicaCount: 0,启用 scale to zero,没请求的时候不占资源。
mode: QueueLength,value: "5",每个 Pod 处理 5 条消息。队列里有 23 条消息,KEDA 就算出需要 ceil(23/5) = 5 个 Pod。
至于 KEDA 怎么连接 RabbitMQ,它通过
TriggerAuthentication从 Kubernetes Secret 里读取连接信息,不在 ScaledObject 里硬编码。具体可以看 demo 仓库的deploy/keda.yaml。
3.4 制造队列积压,观察扩容
端口转发 API。
| |
创建一批任务。
| |
查一下任务状态。
| |
状态流转是 queued -> processing -> completed,整个过程都有时间戳可以看。
打开另一个终端,观察 Worker Pod 数量变化。
| |
你会看到 Worker 从 0 个 Pod 开始,KEDA 检测到队列有积压后,根据我们的配置把 Worker 扩到 4 个 Pod 并发消费。队列清空、冷却期结束后,Worker 又缩回 0。
KEDA 的操作日志也能看到完整过程。
| |
| |
0 -> 1 -> 4 -> 0,这就是 KEDA 事件驱动扩缩容的完整过程。
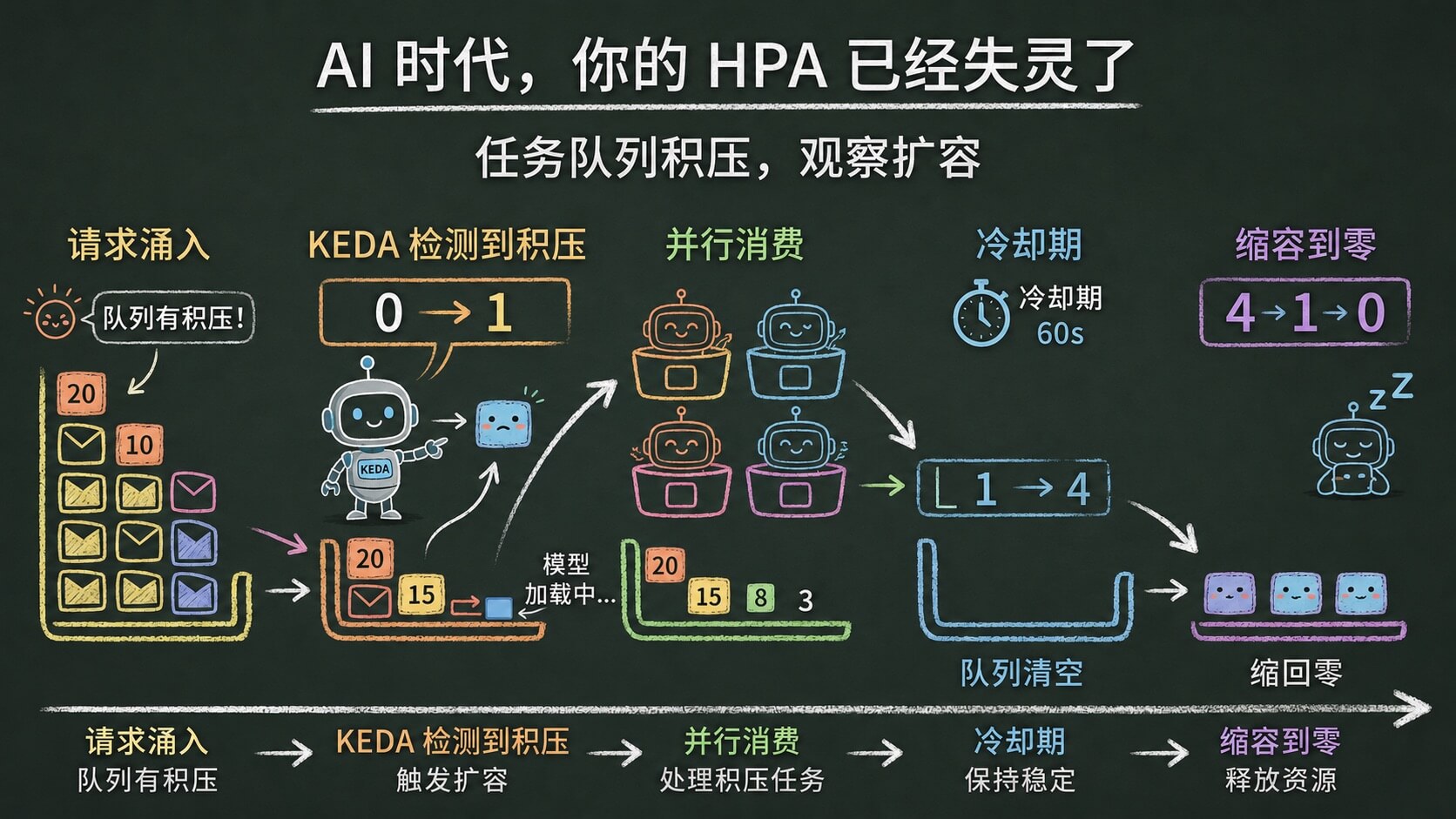
3.5 整个流程
- 用户 POST 一个任务,API 写入 PostgreSQL,同时把 task ID 发到 RabbitMQ
- KEDA 每 5 秒检查 RabbitMQ 队列深度
- 队列有消息,触发器变为 active,KEDA 把 Worker 从 0 扩到计算出的副本数
- 扩出来的 Worker Pod 消费消息,标记任务为 processing,sleep 模拟推理,标记认为为 completed
- 队列消费完,冷却期结束,KEDA 把 Worker 缩回 0
清理环境。
| |
4. 实际使用中需要注意的几个坑
配置写起来简单,但真正使用起来还是有一些需要注意的地方:
冷启动问题。 从 0 扩到 N 意味着 Pod 要从零开始启动,包括加载模型到 GPU。大型图片生成模型的加载可能要 30 秒到 2 分钟,这段时间请求只能排队。如果业务对延迟敏感,最好把 minReplicaCount 设为 1,始终保留一个热 Pod。
cooldownPeriod 别设太短。 缩容后又来请求,重新扩容 + 模型加载,这个周期可能要一两分钟。频繁缩容再扩容的代价很大,Pod 反复启停,GPU 资源白白浪费在模型加载上。建议至少设 300 秒,让流量真正稳定下来再缩。
HPA 会被 KEDA 接管。 KEDA 会在底层创建一个 HPA,所以同一个 Deployment 不能再手动创建 HPA,会冲突。
轮询间隔要权衡。 pollingInterval 设得短,响应快,但对外部系统的 API 调用量也大。如果你有几百个 ScaledObject,每个 5 秒轮询一次,对消息队列的压力不小。根据实际场景在响应速度和资源消耗之间找个平衡点。
聊了这么多,最后收一下。
5. 小结
HPA 在 AI 推理场景下失灵,说到底是它的设计假设,资源使用率跟负载成正比,被 GPU 工作模式打破了。GPU 显存常驻、使用率脉冲、CPU/内存不跟负载走,HPA 看到的信号全是失真的。
KEDA 的思路是绕过资源指标,直接看需求侧的信号。消息队列里有多少消息在排队,就是最真实的扩容依据。
这个思路其实不只适用于 AI 推理,所有异步处理场景都有类似的扩缩容需求。只不过 AI 推理把这个问题放大了,因为 GPU 太贵了,扩错一台就是真金白银的浪费。
几个要点:
- 别看机器忙不忙,看活多不多,队列深度就是 AI 推理服务最真实的扩容信号
- KEDA 支持 scale to zero,GPU 不用的时候不占资源
- 注意冷启动、cooldownPeriod、轮询间隔这几个关键参数
- 没有银弹,KEDA 只是让扩容信号回归准确,模型加载的延迟还得靠预热或其他手段解决
如果你的 AI 推理服务还在用 HPA,建议重新审视一下扩容策略,可能它已经在「失灵」了,只是你还没注意到。