深入 Longhorn 高可用:数据如何在节点故障时依然安全可靠

在云原生时代,存储的高可用性是生产环境的生命线。一个设计良好的存储系统,不仅要能在节点故障时保证数据不丢失,还要做到业务无感知、自动恢复。
本文将深入剖析 Longhorn 的高可用机制:从两层架构设计到 iSCSI 协议的巧妙运用,从多副本写入到 Raft 共识算法,再到自动故障恢复流程。通过理论分析和实战演示,带你彻底理解 Longhorn 如何在分布式环境中实现数据的高可用性。
📚 系列文章:本文是 Longhorn 系列的第二篇,重点剖析高可用原理。如果你还不了解 Longhorn 的基本概念和部署方法,建议先阅读上一篇:云原生分布式存储系统:Longhorn 初体验
1. 架构设计
要理解 Longhorn 的高可用机制,首先需要了解其架构设计。好的架构是高可用的基础。
1.1 两层架构
Longhorn 采用了清晰的分层架构设计:

Longhorn 设计为两层结构:
数据平面(Data Plane)
- Longhorn Engine:存储控制器,每个卷(Volume)一个独立的 Engine
- Replica:数据副本,负责将数据持久化到物理磁盘
控制平面(Control Plane)
- Longhorn Manager:核心控制器,负责调度、管理和监控
这种设计的优势在于:
- 故障隔离:每个 Volume 独立的 Engine,一个卷的问题不会影响其他卷
- 灵活调度:Manager 可以根据节点资源动态调度 Engine 和 Replica
- 易于扩展:数据平面和控制平面解耦,便于独立扩展
1.2 核心组件
在 Kubernetes 中,Longhorn 的核心组件包括:
Longhorn Engine
- 作为 Pod 运行在需要使用卷的节点上
- 每个 Volume 对应一个独立的 Engine 实例
- 负责处理所有 I/O 操作,协调多副本数据同步
Longhorn Replica
- 作为独立进程运行,存储卷数据的完整副本
- 默认创建 3 个副本,分布在不同节点上
- 负责将数据持久化到节点的物理磁盘(默认路径
/var/lib/longhorn)
Longhorn Manager
- 以 DaemonSet 形式运行在每个节点上
- 负责卷的创建、删除、调度和健康监控
- 提供 API 供 CSI Driver 调用
2. 工作流程详解
了解了 Longhorn 的架构设计后,让我们通过一个完整的实例,从 PVC 创建到 Pod 使用,详细了解 Longhorn 的工作流程。
2.1 StorageClass
Longhorn 部署完成后,会自动创建两个 StorageClass:
| |
输出示例:
| |
2.2 创建测试 Pod
让我们通过一个实际例子来演示 Longhorn 的完整工作流程。创建一个使用 Longhorn PVC 的 MariaDB Pod:
| |
2.3 卷创建流程(Provisioning)
当创建 PVC 时,会触发以下流程:
Step 1:PVC 创建
- 用户创建 PVC,指定使用
longhornStorageClass
Step 2:CSI Driver 响应
- Longhorn CSI Driver 监听到 PVC 创建事件
- 调用 Longhorn Manager 的 API,请求创建 Longhorn Volume
Step 3:Volume CRD 创建
- Longhorn Manager 创建对应的
VolumeCRD 对象 - 持续监听 API Server 的响应
| |
输出示例:
| |
Step 4:Engine 和 Replica 调度
- Longhorn Manager 监听到 Volume CRD 创建
- 在 Pod 所在节点创建 Longhorn Engine(专用存储控制器)
- 在多个不同节点创建指定数量的 Replica(默认 3 个)
2.4 卷挂载流程(Attach & Mount)
块设备的挂载分为两个阶段:
阶段 1:Attach(附加到节点)
当 Pod 被调度到某个节点时:
- 该节点的 Kubelet 通过 Longhorn CSI Driver 调用 Longhorn Manager
- Manager 确保 Volume 已准备就绪
- CSI Driver 通过 iSCSI 协议在节点上模拟出一个块设备
查看模拟的块设备:
| |
输出示例:
| |
注意文件类型为 b(block),表示这是一个块设备。
阶段 2:Mount(挂载到 Pod)
Kubelet 将该块设备格式化为文件系统(如 ext4、xfs),并挂载到 Pod 的指定路径。
小结: 通过 Attach 和 Mount 两个阶段,Longhorn 成功将卷挂载到 Pod 中。其中,iSCSI 协议模拟的块设备是实现高可用的关键,它使得 Longhorn 能够拦截所有 I/O 操作,从而实现多副本同步。接下来我们将深入剖析这个高可用机制。
3. 高可用实现原理
3.1 数据写入流程
这是 Longhorn 高可用的核心机制。当应用写入数据时,经历以下流程:
核心思想: 通过 iSCSI 协议模拟块设备,将所有 I/O 操作拦截并转发给 Engine,由 Engine 使用 Raft 算法同步到多个 Replica,实现数据高可用。
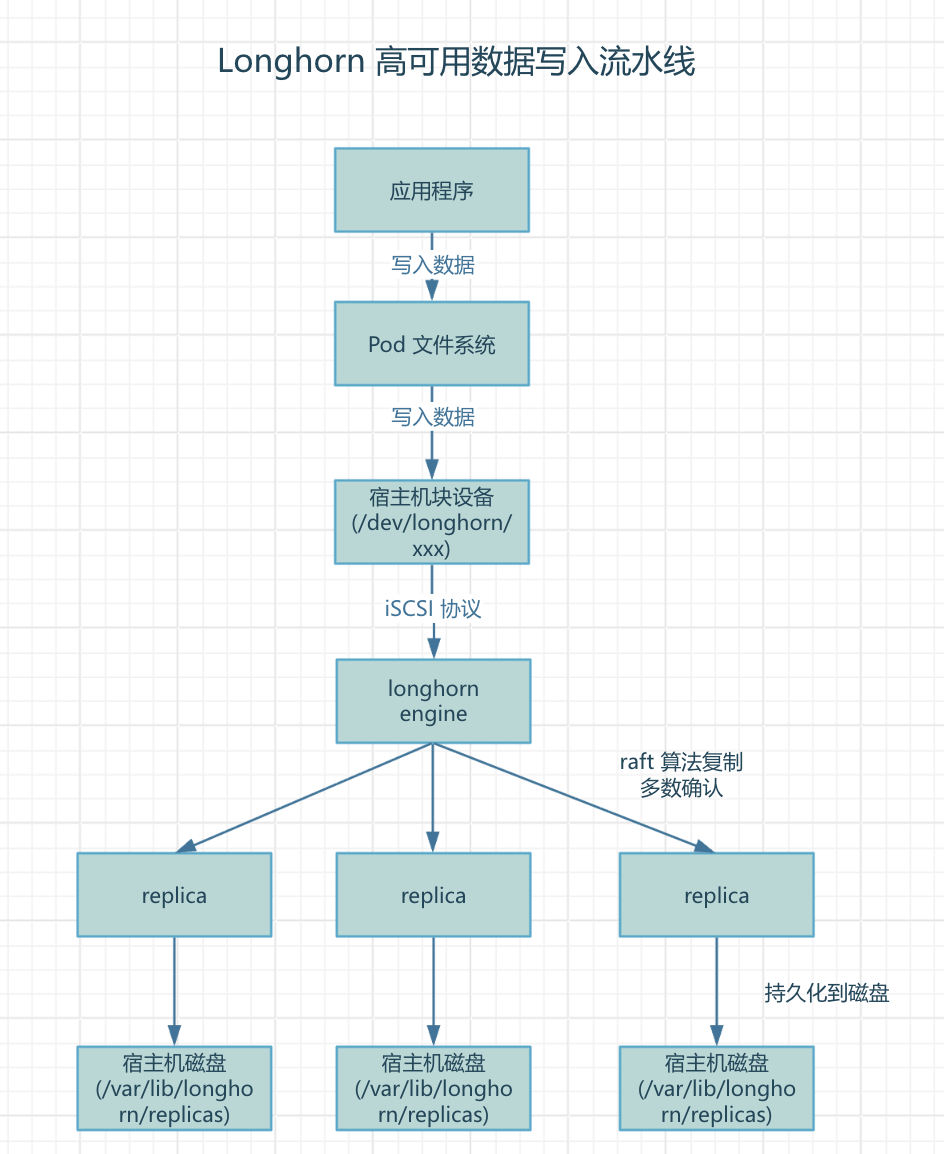
详细步骤:
Step 1:应用写入
- Pod 中的应用(如 MariaDB)向挂载的目录写入数据
- 例如:写入
/bitnami/mariadb/data.db
Step 2:文件系统层
- 数据经过文件系统(ext4/xfs)处理
Step 3:块设备层
- 文件系统将数据写入块设备
/dev/longhorn/xxx
Step 4:iSCSI 协议转发
- 因为这是一个模拟的块设备,写入请求不会直接到达磁盘
- 而是通过 iSCSI 协议转发给 Longhorn Engine
Step 5:Engine 多副本复制
- Engine 接收到写入请求
- 使用 Raft 共识算法将数据同步复制到所有 Replica
- 必须获得多数副本(3个中的2个)的确认后,才返回写入成功
Step 6:Replica 持久化
- 每个 Replica 将数据持久化到其所在节点的物理磁盘
- 默认路径:
/var/lib/longhorn/replicas/<volume-name>-<id>/
关键要点:
- 📍 iSCSI 拦截:通过 iSCSI 协议模拟块设备,实现数据拦截和转发
- 🔄 Raft 共识:使用 Raft 算法确保多副本强一致性
- ✅ 多数派确认:需要 2/3 副本确认才返回写入成功(3副本中至少2个)
- 🛡️ 分布式部署:三副本分布在不同节点,防止单点故障
3.2 关键技术点
从上面的数据写入流程图可以看出,Longhorn 的高可用实现依赖以下关键技术:
1) iSCSI 协议的巧妙运用
与传统存储(如 Ceph)不同,Longhorn 通过 iSCSI 协议模拟了一个块设备,从而能够:
- 拦截所有 I/O 操作:应用的写入不会直接到达磁盘
- 统一数据流向:所有数据必须经过 Engine 处理
- 实现多副本同步:Engine 可以控制数据的复制流程
2) Raft 共识算法
Longhorn 使用 Raft 算法确保数据一致性:
- 强一致性:写入必须获得多数副本确认
- 容错能力:N 个副本可以容忍 (N-1)/2 个副本故障
- 自动选主:Engine 故障时可以自动选举新的 Leader
3) 数据副本分布
| |
Longhorn Manager 会智能调度,确保:
- 同一卷的副本分布在不同节点上
- 避免单点故障风险
- 考虑节点的资源使用情况
4. 故障恢复机制
通过多副本和 Raft 共识算法,Longhorn 实现了数据的高可用性。但真正考验存储系统可靠性的,是当节点故障时的自动恢复能力。本章将详细介绍 Longhorn 如何检测故障、降级运行,并自动重建副本。
4.1 故障检测
健康监控
- Longhorn Manager 持续监控所有节点和组件的健康状态
- Engine 与所有 Replica 保持心跳检测
- 当节点宕机或网络分区时,快速检测到连接丢失
4.2 降级运行
系统降级
- 发现副本故障后,卷状态变为
Degraded(降级) - 但卷仍然继续可用,业务不中断
- 原因:Raft 算法允许多数副本(N/2 + 1)存活时继续工作
举例:3 副本的卷
- 1 个副本故障:剩余 2 个副本形成多数派,继续服务
- 2 个副本故障:只剩 1 个副本,无法形成多数派,只读模式
4.3 自动重建
重建流程
Step 1:检测故障
| |
Step 2:调度新副本
- Longhorn Manager 在健康节点上调度新 Replica
- 选择资源充足且负载较低的节点
Step 3:数据同步
- 新 Replica 启动后,从健康副本同步数据
- 增量同步:只同步差异数据,加快恢复速度
- 同步过程中,卷保持可用状态
Step 4:恢复健康
- 数据同步完成后,新副本加入 Raft 组
- 副本数恢复到预设值(如 3 个)
- 卷状态从
Degraded恢复为Healthy
查看恢复进度:
| |
4.4 故障恢复示例
模拟节点故障:
| |
恢复时间线:
- 0s:节点故障
- ~10s:Longhorn 检测到故障,卷状态变为 Degraded
- ~30s:新副本开始在其他节点上创建
- ~5min:数据同步完成(取决于数据量)
- 完成:卷状态恢复为 Healthy
5. 高可用优势
通过前面的分析,我们深入了解了 Longhorn 的高可用实现机制。那么,与其他存储方案相比,Longhorn 的优势在哪里?它适合什么样的场景?本章将进行详细对比分析。
5.1 与其他方案对比
| 特性 | NFS | Ceph | Longhorn |
|---|---|---|---|
| 高可用性 | ❌ 单点故障 | ✅ 高可用 | ✅ 高可用 |
| 自动故障恢复 | ❌ 需手动处理 | ✅ 自动恢复 | ✅ 自动恢复 |
| 部署复杂度 | ✅ 简单 | ❌ 复杂 | ✅ 简单 |
| 资源占用 | ✅ 低 | ❌ 高 | ✅ 中等 |
| 数据一致性 | ⚠️ 弱一致性 | ✅ 强一致性 | ✅ 强一致性(Raft) |
| 故障容忍度 | 0 | N/2 | N/2 |
5.2 核心优势总结
1. 微服务架构
- 每个 Volume 独立的 Engine,故障隔离
- 便于扩展和维护
2. 强一致性保证
- Raft 共识算法确保数据一致性
- 多数派写入机制
3. 自动故障恢复
- 无需人工干预
- 业务无感知
- 快速数据重建
4. 云原生设计
- 深度集成 Kubernetes
- 使用 CRD 和 Operator 模式
- 声明式 API
6. 小结
本文从架构、原理到实战,全面剖析了 Longhorn 如何实现云原生存储的高可用性。通过数据写入流程图和故障恢复示例,我们深入理解了其背后的核心技术机制:
架构层面
- 采用两层架构设计(数据平面 + 控制平面),职责清晰
- 每个 Volume 独立的 Engine,实现故障隔离
- 多副本设计,默认 3 副本分布在不同节点
技术实现
- 巧妙运用 iSCSI 协议模拟块设备,拦截所有 I/O 操作
- 使用 Raft 共识算法确保多副本数据强一致性
- 写入需要多数副本确认(3个中的2个),平衡性能与可靠性
高可用保证
- 数据多副本:默认 3 副本,可容忍 1 个节点故障
- 自动故障检测:持续监控组件健康状态
- 降级运行:副本故障时卷仍可用,业务不中断
- 自动恢复:在健康节点自动重建副本,增量同步数据
适用场景
- 中小规模生产环境:比 Ceph 轻量,比 NFS 可靠
- 对数据可靠性要求高:强一致性保证
- 希望运维简单:自动故障恢复,无需人工干预
总结
Longhorn 通过精心的架构设计和成熟的分布式算法,在简单性、可靠性和性能之间取得了完美平衡。它的高可用机制不仅理论上完善(Raft 共识、多副本复制),更在实践中证明了可靠性(自动故障恢复、降级运行)。
对于追求"简单可靠"的中小规模 Kubernetes 集群来说,Longhorn 无疑是一个"刚刚好"的云原生存储解决方案——既不会像 NFS 那样让你担心数据安全,也不会像 Ceph 那样让你头疼运维复杂度。