Volcano 三大核心对象解析:Queue、PodGroup、VolcanoJob

上一篇简单介绍了 Volcano 及其使用场景,然后通过 helm 部署并跑通一个最简单的 Demo。
本文主要分析 Volcano 定义的几个主要资源对象的作用,包括 Queue、PodGroup 以及 VolcanoJob。
1. Queue、PodGroup、VolcanoJob 之间的关系
分析前,简单描述下每个对象的作用与定位:
Queue:用于支持多租户场景下的资源分配与任务调度。通过队列,用户可以实现多租资源分配、任务优先级控制、资源抢占与回收等功能,显著提升集群的资源利用率和任务调度效率。
PodGroup: 一组强关联的 Pod 集合,这主要解决了 Kubernetes 原生调度器中单个 Pod 调度的限制。通过将相关的 Pod 组织成 PodGroup,Volcano 能够更有效地处理那些需要多个 Pod 协同工作的批处理工作负载任务。
- 类似于 K8s 中的 Pod,对 kube-scheduler 来说 Pod 是最小调度单元,对 Volcano 来说 PodGroup 是最小调度单元,Volcano 的调度器会以 PodGroup 为单位进行调度,但最终创建的仍是单个 Pod。
VolcanoJob:Volcano 自定义的 Job 资源类型,它扩展了 Kubernetes 的 Job 资源。VolcanoJob 不仅包括了 Kubernetes Job 的所有特性,还加入了对批处理作业的额外支持,使得 Volcano 能够更好地适应高性能和大规模计算任务的需求,更加适用于机器学习、大数据、科学计算等高性能计算场景。
- 和 K8s 中原生的 Workload(deploy、sts、job 等) 作用一样
三者关系如下图所示:
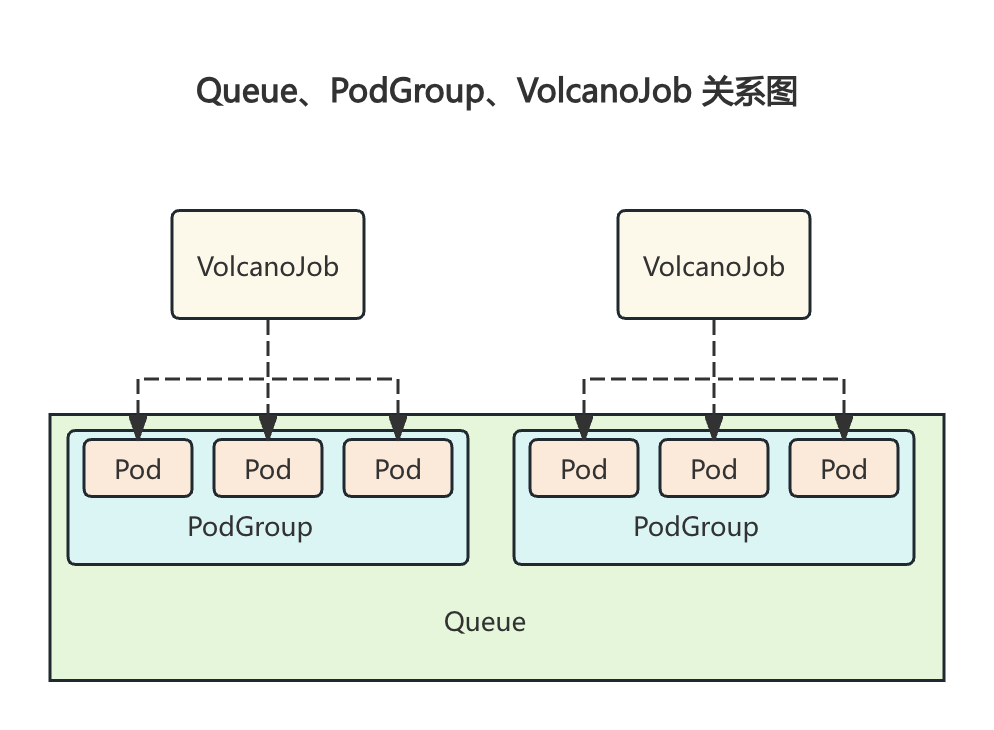
Queue 里面有多个 PodGroup,PodGroup 包含多个 Pod,其中的 Pod 由 VolcanoJob 生成。
一个 VolcanoJob 通常关联一个 PodGroup(自动或手动创建),该 Job 创建的 Pod 也会属于该 PodGroup,Volcano 以 PodGroup 为单位进行统一调度,并从关联的 Queue 中分配资源。
2. Queue
Queue 是Volcano的核心概念之一,用于支持多租户场景下的资源分配与任务调度。通过队列,用户可以实现多租资源分配、任务优先级控制、资源抢占与回收等功能,显著提升集群的资源利用率和任务调度效率。
即:Queue 是容纳一组 PodGroup 的队列,也是该组 PodGroup 获取集群资源的划分依据。
volcano 启动后,会默认创建名为 default 的 queue,weight 为 1。后续下发的 job,若未指定 queue,默认属于default queue。
对于非关键或临时性任务,可以放心使用
defaultqueue;对于重要业务,务必创建专属Queue并设置合适的
weight、priority和reclaimable等配置。
一个简单的 Queue 的 完整 yaml 如下:
| |
关键字段
guarantee,可选:表示该 queue 为自己队列中的所有 PodGroup 预留的资源,其他队列无法使用该部分资源。
- 若需配置 guarantee 值,则需要小于等于 deserved 值的配置
deserved,可选:用于指定该 queue 的应得资源总量
对于 capacity 插件可以直接配置 deserved 直观指定
对于 proportion 插件,会根据 weight 自动计算 deserved
weight,可选:表示该 queue 在集群资源划分中所占的相对比重,该 queue 应得资源总量为 (weight/total_weight) * total_resource。
该字段只有在 proportion 插件开启时可按需配置,若不设置 weight,则默认设置为1
其中, total_weight 表示所有的 queue 的 weight 总和,total_resource 表示集群的资源总量。weight 是一个软约束,取值范围为[1, 2^31-1]
假设有两个 queue,weight 分别为 2 和 1,那么各自可以使用集群 2/3 和 1/3 的资源。
capability,可选:表示该 queue 内所有 podgroup 使用资源量之和的上限,它是一个硬约束。
若不设置该字段,则队列的 capability 会设置为 realCapability(集群的资源总量减去其他队列的总 guarantee值)
一般建议设置 capability 来指定资源上限,以保证集群稳定。
reclaimable,可选:表示该 queue 在资源使用量超过该 queue 所应得的资源份额时,是否允许其他 queue 回收该 queue 使用超额的资源,默认值为true。
- 对于使用 weight 设置资源的 queue 来说,随着 queue 越来越多,total_weight 也越大,当前 queue 分到的资源就会越少,该字段可以控制已经占用的资源是否可以被回收。
priority,可选:表示该 queue 的优先级,在资源分配和资源抢占/回收时,更高优先级的队列将会优先分配/抢占/回收资源
parent,可选:用来指定 queue 的父队列,若未指定 parent,则默认会作为 root queue 的子队列
- Volcano 新增的层级队列功能。
Queue 的字段主要是用于资源限制,包括预留资源量、应得资源量、上限资源量以及是否允许资源回收等核心配置:
guarantee:硬下限,是绝对约束,Queue 为自己队列中所有 PodGroup 预留的资源,其他 Queue 无法占用这部分资源。deserved/weight:软性限制,根据开启不同插件,通过deserved(弹性基准线) 或weight(动态比例) 实现,二者互斥(选其一);capability: 硬上限,该 Queue 内所有 PodGroup 使用资源量之和的上限。reclaimable:是否允许回收超额资源(> deserved 部分)(默认 true,允许回收超额部分)。
资源状态
Queue 包括以下状态
Open:该 queue 当前处于可用状态,可接收新的 PodGroup
Closed:该 queue 当前处于不可用状态,不可接收新的 podgroup
Closing:该 queue 正在转化为不可用状态,不可接收新的 podgroup
Unknown:该 queue 当前处于不可知状态,可能是网络或其他原因导致 queue 的状态暂时无法感知
即:Queue 只有在 Open 状态时可以接收新的 podgroup。
Queue 资源管理
灵活的资源配置
支持多维度资源配额控制(CPU、内存、GPU、NPU等)
支持动态资源配额调整
提供三级资源配置机制:
capability: 队列资源使用上限
deserverd: 资源应得量(在无其他队列提交作业时,该队列内作业所占资源量可超过 deserverd 值,当有多个队列提交作业且集群资源不够用时,超过 deserverd 值的资源量可以被其他队列回收)
guarantee: 资源预留量(预留资源只可被该队列所使用,其他队列无法使用)
建议及注意事项:
进行三级资源配置时,需遵循: guarantee <= deserverd <= capability;
guarantee / capability 可按需配置
deserverd 配置建议:在平级队列场景,所有队列的 deserverd 值总和等于集群资源总量;在层级队列场景,子队列的 deserverd 值总和等于父队列的 deserverd 值,但不能超过父队列的 deserverd 值。
在开启 capacity 插件时需要配置 deserverd 值
在开启 proportion 插件时,会根据 weight 自动计算 deserverd 值
capability 配置注意事项:在层级队列场景,子队列的 capability 值不能超过父队列的 capability 值,若子队列的capability 未设置,则会继承父队列的 capability 值。
智能资源调度
资源借用:允许队列使用其他队列的空闲资源
- 可以临时占用 deserverd 到 capability 范围内的资源
资源回收:当资源紧张时,优先回收超额使用的资源
- 会回收超过 deserverd 的资源
资源抢占:确保高优先级任务的资源需求
队列调度插件
Volcano 提供了两个核心的队列调度插件:
capability 插件支持通过显式配置 deserverd 值来设置队列资源应得量
proportion 插件过配置队列的 Weight 值来自动计算队列资源应得量,无需显式配置 deserverd 值
| |
例如 当前启用的是 proportion 插件:
| |
capability
capacity 插件通过精确的资源配置来进行配额控制,例如:
| |
proportion
proportion 插件通过权重比例自动计算队列的 deserverd 值,当集群资源发生变化时,proportion 插件会自动根据权重比例重新计算各队列的 deserverd 值,无需人工干预。
| |
当集群总资源为 total_resource 时,每个队列的 deserverd 值计算公式为:
| |
其中,queue_weight 表示当前队列的权重,total_weight 表示所有队列权重之和,total_resource 表示集群总资源量。
小结
capacity 插件和 proportion 插件必须二选一,不能同时使用,二者都有有各自的优缺点:
选择哪个插件主要取决于你是想直接设置资源量(capacity 插件)还是通过权重自动计算(proportion 插件):
动态集群选
proportion:若集群频繁扩缩容(如使用 Cluster Autoscaler),优先选proportion避免人工维护成本精细控制选
capacity:需独立管理 CPU/GPU/内存等资源时(如为 AI 队列单独分配 A100 GPU),选capacity实现维度级控制。
Volcano v1.9.0 版本后推荐使用 capacity 插件,因为它提供了更直观的资源配置方式。
用法 & 最佳实践
Weight 资源软约束
背景:
集群 CPU 总量为 4C
已默认创建名为 default 的 queue,weight 为 1
集群中无任务运行
操作:
当前情况下,default queue 可是使用全部集群资源,即 4C。
再创建名为 test 的 queue,weight 为 3。此时,default weight:test weight = 1:3,即 default queue 可使用 1C,test queue 可使用 3C
- total weight 就是 1+3 = 4
创建名为 p1 和 p2 的 podgroup,分别属于 default queue 和 test queue
分别向 p1 和 p2 中投递 job1 和 job2,资源申请量分别为 1C 和 3C,两个 job 均能正常工作
Weight 驱逐资源
由于 Queue 能使用的资源时在 Queue 创建时通过 Weight 按比例划分的,后续有新 Queue 创建时,总 Weight 必然会增加,因此所有旧 Queue 能使用的资源比例肯定会减少。因此就会出现新 Queue 把旧 Queue 多使用的资源驱逐的情况。
背景:
集群 CPU 总量为 4C
已默认创建名为 default 的 queue,weight 为 1
集群中无任务运行
操作:
当前情况下,default queue 可使用全部集群资源,即 4C
创建名为 p1 的 podgroup,属于 default queue。
分别创建名为 job1 和 job2 的 job,属于 p1,资源申请量分别为 1C 和 3C,job1 和 job2 均能正常工作
创建名为 test 的 queue,weight 为 3。此时,default weight:test weight = 1:3,即 default queue 可使用 1C,test queue 可使用 3C。但由于 test queue 内此时无任务,job1 和 job2 仍可正常工作,不会被驱逐。
创建名为 p2 的 podgroup,属于 test queue。
创建名为 job3 的 job,属于 p2,资源申请量为 3C。此时,job2 将被驱逐,将资源归还给 job3,即 default queue 将 3C 资源归还给 test queue。
capability 做硬限制
Weight 只能按比例划分资源,如果不希望 Queue 占用太多资源,那么可以使用 capability 进行硬限制,限制该 Queue 能使用的 CPU、Memory、GPU 等等资源的数量。
背景:
集群 CPU 总量为 4C
已默认创建名为 default 的 queue,weight 为 1
集群中无任务运行
操作:
创建名为 test 的 queue,capability 设置 cpu 为 2C,即 test queue 使用资源上限为 2C
创建名为 p1 的 podgroup,属于 test queue
分别创建名为 job1 和 job2 的 job,属于 p1,资源申请量分别为 1C 和 3C,依次下发。由于 capability 的限制,job1 正常运行,job2 处于 pending 状态
- 虽然按照 Weight 划分该 Queue 能使用 100%资源,即 4C,但是 capability 硬限制只有 2C,job1 占用 1C 后,给 job2 的只有 1C 了。
使用 capability 可以严格限制 queue 中任务使用的资源,但是可能会造成集群资源的浪费,因此使用 weight 还是 capability 需要根据实际情况选择。
reclaimable 的使用
reclaimable: true意味着该队列超量使用的资源(超过其按weight/deserved应得的份额)可以被回收以满足更高优先级队列的需求或本队列内更高优先级PodGroup的需求。reclaimable: false则表示即使超量使用,资源也不可被回收
如果我们的任务优先级比较高,或者不希望被打断,则可以设置 reclaimable: false,避免因为资源问题被回收。
背景:
集群 CPU 总量 为4C
已默认创建名为 default 的 queue,weight 为 1
集群中无任务运行
操作:
创建名为 test 的 queue,reclaimable 设置为 false,weight 为 1。此时,default weight:test weight = 1:1,即default queue 和 test queue 均可使用 2C。
创建名为 p1、p2 的 podgroup,分别属于 test queue 和 default queue
创建名为 job1 的 job,属于 p1,资源申请量 3C,job1 可正常运行。此时,由于 default queue 中尚无任务,test queue 多占用 1C。
创建名为 job2 的 job,属于 p2,资源申请量 2C,任务下发后处于 pending 状态,因为 test queue 的 reclaimable 为 false 导致该 queue 不归还多占的资源,job 无法启动。
小结
Weight 为软约束,只是定义该 Queue 可以使用的资源份额, 是可以超过的(即:占用其他 Queue 未使用的部分资源),需要和 reclaimable 配合使用,当 Queue 使用资源超过 Weight 后,若 reclaimable 为 true 则其他 Queue 申请资源时,调度器会把当前 Queue 中低优先级 Pod 驱逐掉以释放资源。
Capability 为硬约束,不可以超过,资源不够时 Queue 下的 Pod 会直接 Pending
Guarantee 为保留资源,这部分资源不会被其他 queue 抢占。
Priority 优先级, 资源分配和资源抢占/回收生效。
使用
weight(proportion插件) 或deserved(capacity插件) 是为了实现资源共享和弹性,最大化利用集群资源,但可能导致重要任务资源被压缩。使用
capability是为了严格限制一个队列的资源消耗上限(例如防止某个租户过度消耗),避免影响其他队列或系统组件,但可能导致集群整体利用率不高(该队列用不完,其他队列不能用)。使用
guarantee是为了给关键队列提供资源保障,确保其最低资源需求总能满足。
实际生产环境往往是组合使用:为关键业务Queue设置 guarantee + capability + 高 priority + reclaimable: false;为普通业务Queue设置 weight/deserved + capability + reclaimable: true
3. PodGroup
PodGroup 是一组强关联的 Pod 集合,这主要解决了 Kubernetes 原生调度器中单个 Pod 调度的限制。通过将相关的 Pod 组织成 PodGroup,Volcano 能够更有效地处理那些需要多个 Pod 协同工作的批处理工作负载任务。
一个简单的 PodGroup yaml 如下:
| |
关键字段
minMember:表示该 podgroup 下最少需要运行的 pod 或任务数量。如果集群资源不满足 miniMember 数量任务的运行需求,调度器将不会调度任何一个该 podgroup 内的任务。
- 通过设置该字段可以避免无意义的 Pod 调度,只有当满足最小数量时才进行调度。
queue:表示该 podgroup 所属的 queue。
- queue 必须提前已创建且状态为 open。
priorityClassName:表示该 podgroup 的优先级,用于调度器为该 queue 中所有 podgroup 进行调度时进行排序。
system-node-critical和system-cluster-critical是2个预留的值,表示最高优先级。不特别指定时,默认使用 default 优先级或 zero 优先级。
minResources:表示运行该 podgroup 所需要的最少资源。当集群可分配资源不满足 minResources 时,调度器将不会调度任何一个该 podgroup 内的任务。
以下为 status 部分
phase:表示该 podgroup 当前的状态。
conditions:表示该 podgroup 的具体状态日志,包含了 podgroup 生命周期中的关键事件。
running:表示该 podgroup 中当前处于 running 状态的 pod 或任务的数量。
succeed:表示该 podgroup 中当前处于 succeed 状态的 pod 或任务的数量。
failed:表示该 podgroup 中当前处于 failed 状态的 pod 或任务的数量。
资源状态
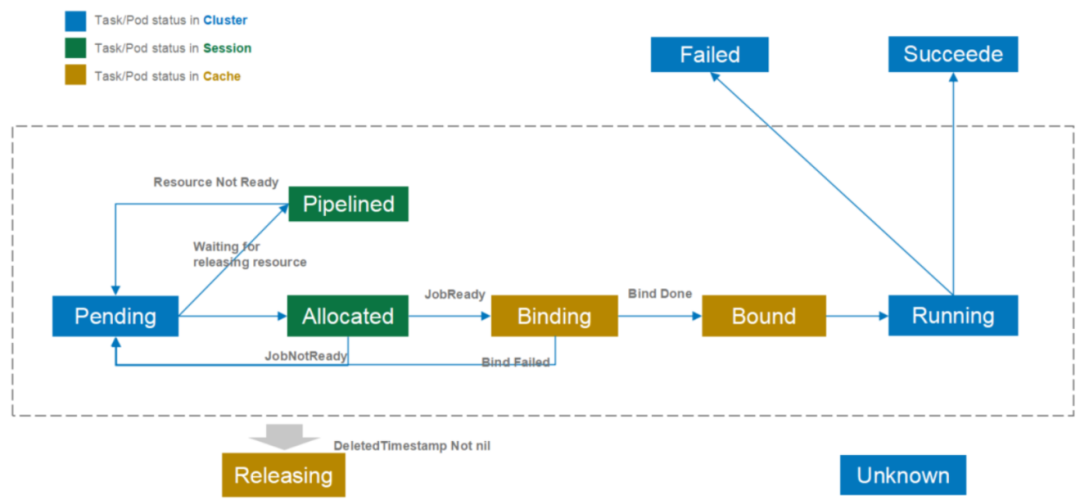
pending:表示该 podgroup 已经被 volcano 接纳,但是集群资源暂时不能满足它的需求。一旦资源满足,该 podgroup 将转变为 running 状态。
inqueue:表示该 podgroup 已经通过了调度器的校验并入队,即将为它分配资源。inqueue 是一种处于 pending和 running 之间的中间状态。
running:表示该 podgroup 至少有 minMember 个 pod 或任务处于 running 状态。
unknown:表示该 podgroup 中 minMember 数量的 pod 或任务分为 2 种状态,部分处于 running 状态,部分没有被调度。没有被调度的原因可能是资源不够等。调度器将等待 controller 重新拉起这些 pod 或任务。
状态流转如下图所示:
自动创建 PodGroup
Volcano 会为每个 VolcanoJob 自动创建一个同名 PodGroup,若需自定义 PodGroup,可通过 spec.podGroup 字段指定。
自动创建的 PodGroup 取值如下:
minMember 默认为 vcjob 中所有 Task 的副本数总和,如果 vcjob 中指定了 minAvailable 则直接使用 minAvailable 填充
minResources 则是所有 Task 资源总和,当
minAvailable存在时,minResources 按 前 minAvailable 个 Pod 的资源总和计算,且顺序由 Task 在 VolcanoJob 中的定义顺序决定
举个栗子🌰:
下面这个 vcjob 包含两个 task,nginx1 和 nginx2,副本数分别为 2 和 4,申请资源也不同。
| |
当我们不指定 vcjob 中的minAvailable 参数时自动创建的 PodGroup 如下:
| |
minMember 为 6,包括了 vcjob 中两个 task 的副本数之和
minResources 则是包括了两个 task 对应的 6 个 Pod 所需资源总和
当我们指定 vcjob 中的 minAvailable=3 时自动创建的 PodGroup 如下:
| |
minMember 为 3,直接使用 minAvailable 填充
minResources 则是只计算了前 3 个 Pod 所需的资源
minResources 是按照 task 定义的先后顺序计算的,这 3 个 Pod 包括 nginx2 中的两个和 nginx1 中的 1 个,如果调整 task 的顺序,minResources 也会变化。
例如,将 task nginx1 放前面,生成的 PodGroup 如下:
| |
这里计算的 3 个 Pod 都是 nginx1 中的 Pod。
用法 & 最佳实践
minMember 的使用
在某些场景下,可能需要至少启动 N 个 Pod 本次任务才会成功,如机器学习训练,这种情况下适合使用 minMember 字段。
例如:本次训练要启动 6 个 Pod,如果不能都启动那整体任务肯定会失败,这种情况直接把 minMember 设置为 6,这样就可以保证只有 6 个 Pod 都可以启动时才会真正调度。
priorityClassName 的使用
priorityClassName 用于 podgroup 的优先级排序,可用于任务抢占调度场景。它本身也是一种资源。
minResources 的使用
在某些场景下,任务的运行必须满足最小资源要求,不满足则不能运行该任务,如某些大数据分析场景。这种情况下适合使用 minResources 字段。
使用 vcjob
对于下面这个 vcjob,task 会启动 3 个 Pod,同时 minAvailable 也设置为 3。
| |
该 vcjob 创建后自动生成的 PodGroup 如下:
| |
使用 k8s 原生工作负载
除了通过 vcjob 创建工作负载之外,也可以使用 k8s 原生工作负载。
| |
通过 Annoations
scheduling.volcano.sh/queue-name指定 queue并通过 schedulerName 指定调度为 volcano
4. VolcanoJob
VolcanoJob 是 Volcano 自定义的 Job 资源类型,它扩展了 Kubernetes 的 Job 资源。VolcanoJob 不仅包括了 Kubernetes Job 的所有特性,还加入了对批处理作业的额外支持,使得 Volcano 能够更好地适应高性能和大规模计算任务的需求,更加适用于机器学习、大数据、科学计算等高性能计算场景。
一个简单的 VolcanoJob yaml 如下:
| |
关键字段
schedulerName:表示该 job 的 pod所 使用的调度器,默认值为 volcano,也可指定为 default-scheduler。它也是 tasks.template.spec.schedulerName 的默认值。
如果指定为
default-scheduler,则意味着该Job的Pod将由Kubernetes默认调度器调度,将无法利用Volcano提供的高级调度策略(如Gang Scheduling, Fair-Share, Queue, Preemption等)强烈建议对于需要Volcano特性的Job保持
schedulerName: volcano
minAvailable:表示运行该 job 所要运行的最少 pod 数量。只有当 job 中处于 running 状态的 pod 数量不小于minAvailable 时,才认为该 job 运行正常。
- 用于控制什么时候才切换该任务到 running 状态。
volumes:表示该j ob 的挂卷配置。volumes 配置遵从 kubernetes volumes 配置要求。
tasks.replicas:表示某个 task pod 的副本数。
tasks.template:表示某个 task pod 的具体配置定义。
tasks.policies:表示某个 task 的生命周期策略。
policies:表示 job 中所有 task 的默认生命周期策略,在 tasks.policies 不配置时使用该策略。
plugins:表示该 job 在调度过程中使用的插件。
queue:表示该 job 所属的队列。
priorityClassName:表示该 job 优先级,在抢占调度和优先级排序中生效。
maxRetry:表示当该 job 可以进行的最大重启次数。
相比之下,VolcanoJob 的字段都比较容易理解,大分部含义和 K8s 原生对象中的字段含义一致。
资源状态
pending:表示 job 还在等待调度中,处于排队的状态。
aborting:表示 job 因为某种外界原因正处于中止状态,即将进入 aborted 状态。
aborted:表示 job 因为某种外界原因已处于中止状态。
running:表示 job 中至少有 minAvailable 个 pod 正在运行状态。
restarting:表示 job 正处于重启状态,正在中止当前的 job 实例并重新创建新的实例。
completing:表示 job 中至少有 minAvailable 个数的 task 已经完成,该 job 正在进行最后的清理工作。
completed:表示 job 中至少有 minAvailable 个数的 task 已经完成,该 job 已经完成了最后的清理工作。
terminating:表示 job 因为某种内部原因正处于终止状态,正在等到 pod 或 task 释放资源。
terminated:表示 job 因为某种内部原因已经处于终止状态,job 没有达到预期就结束了。
failed:表示 job 经过了 maxRetry 次重启,依然没有正常启动。
用法
Tensorflow
以 tensorflow 为例,创建一个具有 1 个 ps 和 2 个 worker 的工作负载。
| |
MindSpore
以 MindSpore 为例,创建一个具有 8 个 pod 副本的工作负载,要求 1 个可用即可。
| |
5. 小结
Queue 实现多租户资源隔离与弹性分配
通过权重(weight)或容量(deserved)策略动态划分集群资源,支持资源预留(guarantee)、硬上限(capability)和弹性复用(reclaimable)。例如:
多租户隔离:为不同团队/项目分配独立队列,避免资源抢占
弹性分配:空闲时超用资源,紧张时按比例回收,提升集群利用率
层级扩展:支持父/子队列嵌套,实现部门级资源再分配
PodGroup 确保强关联 Pod 的原子调度(Gang Scheduling)
通过 minMember 和 minResources 实现 All-or-Nothing 调度,解决分布式任务(如AI训练)的协同启动问题。例如:
原子性保障:若集群无法满足最小Pod数,则全部不调度,避免死锁
优先级控制:通过
priorityClassName实现任务抢占,保障高优先级作业
VolcanoJob 定义复杂作业结构与生命周期策略
多任务模板:支持异构Pod角色(如TensorFlow的PS/Worker),通过
tasks字段声明依赖关系增强生命周期:基于
policies配置故障恢复(如Pod失败重启)、超时终止(如PodPending: 10m自动终止)插件扩展:集成
ssh/svc/env等插件,提供跨Pod互信、服务发现等分布式能力
一句话描述:Queue 是资源池,实现多租户资源隔离与动态分配;PodGroup 是原子调度单元,确保强关联 Pod 的协同调度(All-or-Nothing);VolcanoJob 是批作业抽象,定义多角色任务拓扑与生命周期策略。