func(p*iluvatarDevicePlugin)allocateDevicesByDeviceID(hostminoruint,numint)*pluginapi.DeviceSpec{vardevicepluginapi.DeviceSpechostPathPrefix:="/dev/"containerPathPrefix:="/dev/"// Expose the device node for iluvatar pod.device.HostPath=hostPathPrefix+deviceName+strconv.Itoa(int(hostminor))device.ContainerPath=containerPathPrefix+deviceName+strconv.Itoa(num)device.Permissions="rw"return&device}
不过由于没有挂载驱动进去,因此需要容器内自带驱动才行。
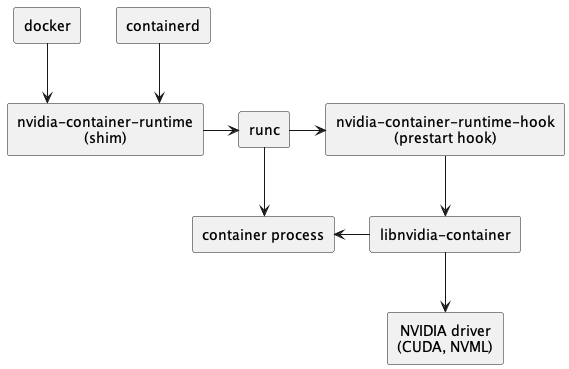
至此,已经分析了 k8s 创建 Pod 使用 GPU 的整个流程及大致原理,接下来简单分析下相关组件源码。
// https://github.com/NVIDIA/k8s-device-plugin/blob/main/internal/plugin/server.go#L319-L332// Allocate which return list of devices.func(plugin*NvidiaDevicePlugin)Allocate(ctxcontext.Context,reqs*pluginapi.AllocateRequest)(*pluginapi.AllocateResponse,error){responses:=pluginapi.AllocateResponse{}for_,req:=rangereqs.ContainerRequests{iferr:=plugin.rm.ValidateRequest(req.DevicesIDs);err!=nil{returnnil,fmt.Errorf("invalid allocation request for %q: %w",plugin.rm.Resource(),err)}response,err:=plugin.getAllocateResponse(req.DevicesIDs)iferr!=nil{returnnil,fmt.Errorf("failed to get allocate response: %v",err)}responses.ContainerResponses=append(responses.ContainerResponses,response)}return&responses,nil}
func(plugin*NvidiaDevicePlugin)getAllocateResponse(requestIds[]string)(*pluginapi.ContainerAllocateResponse,error){deviceIDs:=plugin.deviceIDsFromAnnotatedDeviceIDs(requestIds)// Create an empty response that will be updated as required below.response:=&pluginapi.ContainerAllocateResponse{Envs:make(map[string]string),}ifplugin.deviceListStrategies.AnyCDIEnabled(){responseID:=uuid.New().String()iferr:=plugin.updateResponseForCDI(response,responseID,deviceIDs...);err!=nil{returnnil,fmt.Errorf("failed to get allocate response for CDI: %v",err)}}ifplugin.config.Sharing.SharingStrategy()==spec.SharingStrategyMPS{plugin.updateResponseForMPS(response)}// The following modifications are only made if at least one non-CDI device// list strategy is selected.ifplugin.deviceListStrategies.AllCDIEnabled(){returnresponse,nil}ifplugin.deviceListStrategies.Includes(spec.DeviceListStrategyEnvvar){plugin.updateResponseForDeviceListEnvvar(response,deviceIDs...)}ifplugin.deviceListStrategies.Includes(spec.DeviceListStrategyVolumeMounts){plugin.updateResponseForDeviceMounts(response,deviceIDs...)}if*plugin.config.Flags.Plugin.PassDeviceSpecs{response.Devices=append(response.Devices,plugin.apiDeviceSpecs(*plugin.config.Flags.NvidiaDevRoot,requestIds)...)}if*plugin.config.Flags.GDSEnabled{response.Envs["NVIDIA_GDS"]="enabled"}if*plugin.config.Flags.MOFEDEnabled{response.Envs["NVIDIA_MOFED"]="enabled"}returnresponse,nil}
可以看到,根据不同 flag 以及策略分为不同的设置方式
1
2
3
4
5
6
7
// Constants to represent the various device list strategiesconst(DeviceListStrategyEnvvar="envvar"DeviceListStrategyVolumeMounts="volume-mounts"DeviceListStrategyCDIAnnotations="cdi-annotations"DeviceListStrategyCDICRI="cdi-cri")
// updateResponseForDeviceListEnvvar sets the environment variable for the requested devices.func(plugin*NvidiaDevicePlugin)updateResponseForDeviceListEnvvar(response*pluginapi.ContainerAllocateResponse,deviceIDs...string){response.Envs[plugin.deviceListEnvvar]=strings.Join(deviceIDs,",")}
// https://github.com/NVIDIA/nvidia-containertoolkit/blob/main/internal/runtime/api.go#L17-L26typertstruct{logger*LoggermodeOverridestring}// Interface is the interface for the runtime library.typeInterfaceinterface{Run([]string)error}funcNew(opts...Option)Interface{r:=rt{}for_,opt:=rangeopts{opt(&r)}ifr.logger==nil{r.logger=NewLogger()}return&r}
// https://github.com/NVIDIA/nvidia-container-toolkit/blob/main/internal/runtime/runtime.go#L34-L91// Run is an entry point that allows for idiomatic handling of errors// when calling from the main function.func(rrt)Run(argv[]string)(rerrerror){deferfunc(){ifrerr!=nil{r.logger.Errorf("%v",rerr)}}()printVersion:=hasVersionFlag(argv)ifprintVersion{fmt.Printf("%v version %v\n","NVIDIA Container Runtime",info.GetVersionString(fmt.Sprintf("spec: %v",specs.Version)))}cfg,err:=config.GetConfig()iferr!=nil{returnfmt.Errorf("error loading config: %v",err)}r.logger.Update(cfg.NVIDIAContainerRuntimeConfig.DebugFilePath,cfg.NVIDIAContainerRuntimeConfig.LogLevel,argv,)deferfunc(){ifrerr!=nil{r.logger.Errorf("%v",rerr)}iferr:=r.logger.Reset();err!=nil{rerr=errors.Join(rerr,fmt.Errorf("failed to reset logger: %v",err))}}()// We apply some config updates here to ensure that the config is valid in// all cases.ifr.modeOverride!=""{cfg.NVIDIAContainerRuntimeConfig.Mode=r.modeOverride}//nolint:staticcheck // TODO(elezar): We should swith the nvidia-container-runtime from using nvidia-ctk to using nvidia-cdi-hook.cfg.NVIDIACTKConfig.Path=config.ResolveNVIDIACTKPath(&logger.NullLogger{},cfg.NVIDIACTKConfig.Path)cfg.NVIDIAContainerRuntimeHookConfig.Path=config.ResolveNVIDIAContainerRuntimeHookPath(&logger.NullLogger{},cfg.NVIDIAContainerRuntimeHookConfig.Path)// Log the config at Trace to allow for debugging if required.r.logger.Tracef("Running with config: %+v",cfg)driver:=root.New(root.WithLogger(r.logger),root.WithDriverRoot(cfg.NVIDIAContainerCLIConfig.Root),)r.logger.Tracef("Command line arguments: %v",argv)runtime,err:=newNVIDIAContainerRuntime(r.logger,cfg,argv,driver)iferr!=nil{returnfmt.Errorf("failed to create NVIDIA Container Runtime: %v",err)}ifprintVersion{fmt.Print("\n")}returnruntime.Exec(argv)}
核心部分:
1
2
3
4
5
6
7
8
9
runtime,err:=newNVIDIAContainerRuntime(r.logger,cfg,argv,driver)iferr!=nil{returnfmt.Errorf("failed to create NVIDIA Container Runtime: %v",err)}ifprintVersion{fmt.Print("\n")}returnruntime.Exec(argv)
// https://github.com/NVIDIA/nvidia-container-toolkit/blob/main/internal/runtime/runtime_factory.go#L32-L62// newNVIDIAContainerRuntime is a factory method that constructs a runtime based on the selected configuration and specified loggerfuncnewNVIDIAContainerRuntime(loggerlogger.Interface,cfg*config.Config,argv[]string,driver*root.Driver)(oci.Runtime,error){lowLevelRuntime,err:=oci.NewLowLevelRuntime(logger,cfg.NVIDIAContainerRuntimeConfig.Runtimes)iferr!=nil{returnnil,fmt.Errorf("error constructing low-level runtime: %v",err)}logger.Tracef("Using low-level runtime %v",lowLevelRuntime.String())if!oci.HasCreateSubcommand(argv){logger.Tracef("Skipping modifier for non-create subcommand")returnlowLevelRuntime,nil}ociSpec,err:=oci.NewSpec(logger,argv)iferr!=nil{returnnil,fmt.Errorf("error constructing OCI specification: %v",err)}specModifier,err:=newSpecModifier(logger,cfg,ociSpec,driver)iferr!=nil{returnnil,fmt.Errorf("failed to construct OCI spec modifier: %v",err)}// Create the wrapping runtime with the specified modifier.r:=oci.NewModifyingRuntimeWrapper(logger,lowLevelRuntime,ociSpec,specModifier,)returnr,nil}
// newSpecModifier is a factory method that creates constructs an OCI spec modifer based on the provided config.funcnewSpecModifier(loggerlogger.Interface,cfg*config.Config,ociSpecoci.Spec,driver*root.Driver)(oci.SpecModifier,error){rawSpec,err:=ociSpec.Load()iferr!=nil{returnnil,fmt.Errorf("failed to load OCI spec: %v",err)}image,err:=image.NewCUDAImageFromSpec(rawSpec)iferr!=nil{returnnil,err}mode:=info.ResolveAutoMode(logger,cfg.NVIDIAContainerRuntimeConfig.Mode,image)modeModifier,err:=newModeModifier(logger,mode,cfg,ociSpec,image)iferr!=nil{returnnil,err}// For CDI mode we make no additional modifications.ifmode=="cdi"{returnmodeModifier,nil}graphicsModifier,err:=modifier.NewGraphicsModifier(logger,cfg,image,driver)iferr!=nil{returnnil,err}featureModifier,err:=modifier.NewFeatureGatedModifier(logger,cfg,image)iferr!=nil{returnnil,err}modifiers:=modifier.Merge(modeModifier,graphicsModifier,featureModifier,)returnmodifiers,nil}
func(mstableRuntimeModifier)Modify(spec*specs.Spec)error{// If an NVIDIA Container Runtime Hook already exists, we don't make any modifications to the spec.ifspec.Hooks!=nil{for_,hook:=rangespec.Hooks.Prestart{hook:=hookifisNVIDIAContainerRuntimeHook(&hook){m.logger.Infof("Existing nvidia prestart hook (%v) found in OCI spec",hook.Path)returnnil}}}path:=m.nvidiaContainerRuntimeHookPathm.logger.Infof("Using prestart hook path: %v",path)args:=[]string{filepath.Base(path)}ifspec.Hooks==nil{spec.Hooks=&specs.Hooks{}}spec.Hooks.Prestart=append(spec.Hooks.Prestart,specs.Hook{Path:path,Args:append(args,"prestart"),})returnnil}
funcdoPrestart(){varerrerrordeferexit()log.SetFlags(0)hook,err:=getHookConfig()iferr!=nil||hook==nil{log.Panicln("error getting hook config:",err)}cli:=hook.NVIDIAContainerCLIConfigcontainer:=getContainerConfig(*hook)nvidia:=container.Nvidiaifnvidia==nil{// Not a GPU container, nothing to do.return}if!hook.NVIDIAContainerRuntimeHookConfig.SkipModeDetection&&info.ResolveAutoMode(&logInterceptor{},hook.NVIDIAContainerRuntimeConfig.Mode,container.Image)!="legacy"{log.Panicln("invoking the NVIDIA Container Runtime Hook directly (e.g. specifying the docker --gpus flag) is not supported. Please use the NVIDIA Container Runtime (e.g. specify the --runtime=nvidia flag) instead.")}rootfs:=getRootfsPath(container)args:=[]string{getCLIPath(cli)}ifcli.Root!=""{args=append(args,fmt.Sprintf("--root=%s",cli.Root))}ifcli.LoadKmods{args=append(args,"--load-kmods")}ifcli.NoPivot{args=append(args,"--no-pivot")}if*debugflag{args=append(args,"--debug=/dev/stderr")}elseifcli.Debug!=""{args=append(args,fmt.Sprintf("--debug=%s",cli.Debug))}ifcli.Ldcache!=""{args=append(args,fmt.Sprintf("--ldcache=%s",cli.Ldcache))}ifcli.User!=""{args=append(args,fmt.Sprintf("--user=%s",cli.User))}args=append(args,"configure")ifldconfigPath:=cli.NormalizeLDConfigPath();ldconfigPath!=""{args=append(args,fmt.Sprintf("--ldconfig=%s",ldconfigPath))}ifcli.NoCgroups{args=append(args,"--no-cgroups")}iflen(nvidia.Devices)>0{args=append(args,fmt.Sprintf("--device=%s",nvidia.Devices))}iflen(nvidia.MigConfigDevices)>0{args=append(args,fmt.Sprintf("--mig-config=%s",nvidia.MigConfigDevices))}iflen(nvidia.MigMonitorDevices)>0{args=append(args,fmt.Sprintf("--mig-monitor=%s",nvidia.MigMonitorDevices))}iflen(nvidia.ImexChannels)>0{args=append(args,fmt.Sprintf("--imex-channel=%s",nvidia.ImexChannels))}for_,cap:=rangestrings.Split(nvidia.DriverCapabilities,","){iflen(cap)==0{break}args=append(args,capabilityToCLI(cap))}for_,req:=rangenvidia.Requirements{args=append(args,fmt.Sprintf("--require=%s",req))}args=append(args,fmt.Sprintf("--pid=%s",strconv.FormatUint(uint64(container.Pid),10)))args=append(args,rootfs)env:=append(os.Environ(),cli.Environment...)//nolint:gosec // TODO: Can we harden this so that there is less risk of command injection?err=syscall.Exec(args[0],args,env)log.Panicln("exec failed:",err)}
funcgetContainerConfig(hookHookConfig)(configcontainerConfig){varhHookStated:=json.NewDecoder(os.Stdin)iferr:=d.Decode(&h);err!=nil{log.Panicln("could not decode container state:",err)}b:=h.Bundleiflen(b)==0{b=h.BundlePath}s:=loadSpec(path.Join(b,"config.json"))image,err:=image.New(image.WithEnv(s.Process.Env),image.WithDisableRequire(hook.DisableRequire),)iferr!=nil{log.Panicln(err)}privileged:=isPrivileged(s)returncontainerConfig{Pid:h.Pid,Rootfs:s.Root.Path,Image:image,Nvidia:getNvidiaConfig(&hook,image,s.Mounts,privileged),}}
funcgetNvidiaConfig(hookConfig*HookConfig,imageimage.CUDA,mounts[]Mount,privilegedbool)*nvidiaConfig{legacyImage:=image.IsLegacy()vardevicesstringifd:=getDevices(hookConfig,image,mounts,privileged);d!=nil{devices=*d}else{// 'nil' devices means this is not a GPU container.returnnil}varmigConfigDevicesstringifd:=getMigConfigDevices(image);d!=nil{migConfigDevices=*d}if!privileged&&migConfigDevices!=""{log.Panicln("cannot set MIG_CONFIG_DEVICES in non privileged container")}varmigMonitorDevicesstringifd:=getMigMonitorDevices(image);d!=nil{migMonitorDevices=*d}if!privileged&&migMonitorDevices!=""{log.Panicln("cannot set MIG_MONITOR_DEVICES in non privileged container")}varimexChannelsstringifc:=getImexChannels(image);c!=nil{imexChannels=*c}driverCapabilities:=hookConfig.getDriverCapabilities(image,legacyImage).String()requirements,err:=image.GetRequirements()iferr!=nil{log.Panicln("failed to get requirements",err)}return&nvidiaConfig{Devices:devices,MigConfigDevices:migConfigDevices,MigMonitorDevices:migMonitorDevices,ImexChannels:imexChannels,DriverCapabilities:driverCapabilities,Requirements:requirements,}}
funcgetDevices(hookConfig*HookConfig,imageimage.CUDA,mounts[]Mount,privilegedbool)*string{// If enabled, try and get the device list from volume mounts firstifhookConfig.AcceptDeviceListAsVolumeMounts{devices:=getDevicesFromMounts(mounts)ifdevices!=nil{returndevices}}// Fallback to reading from the environment variable if privileges are correctdevices:=getDevicesFromEnvvar(image,hookConfig.getSwarmResourceEnvvars())ifdevices==nil{returnnil}ifprivileged||hookConfig.AcceptEnvvarUnprivileged{returndevices}configName:=hookConfig.getConfigOption("AcceptEnvvarUnprivileged")log.Printf("Ignoring devices specified in NVIDIA_VISIBLE_DEVICES (privileged=%v, %v=%v) ",privileged,configName,hookConfig.AcceptEnvvarUnprivileged)returnnil}
envNVVisibleDevices="NVIDIA_VISIBLE_DEVICES"funcgetDevicesFromEnvvar(imageimage.CUDA,swarmResourceEnvvars[]string)*string{// We check if the image has at least one of the Swarm resource envvars defined and use this// if specified.varhasSwarmEnvvarboolfor_,envvar:=rangeswarmResourceEnvvars{ifimage.HasEnvvar(envvar){hasSwarmEnvvar=truebreak}}vardevices[]stringifhasSwarmEnvvar{devices=image.DevicesFromEnvvars(swarmResourceEnvvars...).List()}else{devices=image.DevicesFromEnvvars(envNVVisibleDevices).List()}iflen(devices)==0{returnnil}devicesString:=strings.Join(devices,",")return&devicesString}
// Environment variable unset with legacy image: default to "all".if!isSet&&len(devices)==0&&i.IsLegacy(){returnNewVisibleDevices("all")}
那么什么算是 legacy image 呢:
1
2
3
4
5
6
7
8
// IsLegacy returns whether the associated CUDA image is a "legacy" image. An// image is considered legacy if it has a CUDA_VERSION environment variable defined// and no NVIDIA_REQUIRE_CUDA environment variable defined.func(iCUDA)IsLegacy()bool{legacyCudaVersion:=i.env[envCUDAVersion]cudaRequire:=i.env[envNVRequireCUDA]returnlen(legacyCudaVersion)>0&&len(cudaRequire)==0}
这也就是为什么,有时候启动 Pod 并没有申请 GPU,但是 Pod 里面依旧可以看到所有 GPU,就是走了这个 legacy image 的分支逻辑。