// pkg/kubelet/kubelet.go#L1397func(kl*Kubelet)StartGarbageCollection(){loggedContainerGCFailure:=falsegowait.Until(func(){ctx:=context.Background()iferr:=kl.containerGC.GarbageCollect(ctx);err!=nil{klog.ErrorS(err,"Container garbage collection failed")kl.recorder.Eventf(kl.nodeRef,v1.EventTypeWarning,events.ContainerGCFailed,err.Error())loggedContainerGCFailure=true}else{varvLevelklog.Level=4ifloggedContainerGCFailure{vLevel=1loggedContainerGCFailure=false}klog.V(vLevel).InfoS("Container garbage collection succeeded")}},ContainerGCPeriod,wait.NeverStop)// 每 1 分钟执行一次容器垃圾回收// 一个特殊逻辑,如果把参数设置为 100 可以跳过垃圾回收// when the high threshold is set to 100, stub the image GC managerifkl.kubeletConfiguration.ImageGCHighThresholdPercent==100{klog.V(2).InfoS("ImageGCHighThresholdPercent is set 100, Disable image GC")return}prevImageGCFailed:=falsegowait.Until(func(){ctx:=context.Background()iferr:=kl.imageManager.GarbageCollect(ctx);err!=nil{ifprevImageGCFailed{klog.ErrorS(err,"Image garbage collection failed multiple times in a row")// Only create an event for repeated failureskl.recorder.Eventf(kl.nodeRef,v1.EventTypeWarning,events.ImageGCFailed,err.Error())}else{klog.ErrorS(err,"Image garbage collection failed once. Stats initialization may not have completed yet")}prevImageGCFailed=true}else{varvLevelklog.Level=4ifprevImageGCFailed{vLevel=1prevImageGCFailed=false}klog.V(vLevel).InfoS("Image garbage collection succeeded")}},ImageGCPeriod,wait.NeverStop)// 每 5 分钟执行一次镜像垃圾回收}
间隔时间则是前面提到的 1 分钟和 5 分钟
1
2
3
4
// ContainerGCPeriod is the period for performing container garbage collection.ContainerGCPeriod=time.Minute// ImageGCPeriod is the period for performing image garbage collection.ImageGCPeriod=5*time.Minute
驱逐逻辑中强制触发
实际上除了前面的两个 goroutine 之外还有驱逐逻辑里也会直接调用相关垃圾回收功能,在满足驱逐 Pod 的条件之后,Kubelet 也会直接调用垃圾回收功能,尝试清理资源,以减少对 Pod 的驱逐,从而提升稳定性。
func(m*managerImpl)Start(diskInfoProviderDiskInfoProvider,podFuncActivePodsFunc,podCleanedUpFuncPodCleanedUpFunc,monitoringIntervaltime.Duration){thresholdHandler:=func(messagestring){klog.InfoS(message)m.synchronize(diskInfoProvider,podFunc)}ifm.config.KernelMemcgNotification{for_,threshold:=rangem.config.Thresholds{ifthreshold.Signal==evictionapi.SignalMemoryAvailable||threshold.Signal==evictionapi.SignalAllocatableMemoryAvailable{notifier,err:=NewMemoryThresholdNotifier(threshold,m.config.PodCgroupRoot,&CgroupNotifierFactory{},thresholdHandler)iferr!=nil{klog.InfoS("Eviction manager: failed to create memory threshold notifier","err",err)}else{gonotifier.Start()m.thresholdNotifiers=append(m.thresholdNotifiers,notifier)}}}}// start the eviction manager monitoringgofunc(){for{ifevictedPods:=m.synchronize(diskInfoProvider,podFunc);evictedPods!=nil{klog.InfoS("Eviction manager: pods evicted, waiting for pod to be cleaned up","pods",klog.KObjSlice(evictedPods))m.waitForPodsCleanup(podCleanedUpFunc,evictedPods)}else{time.Sleep(monitoringInterval)}}}()}
其中启动了一个 goroutine 一直在调用 synchronize 方法,判断是否有 Pod 需要驱逐,synchronize 方法如下:
func(m*managerImpl)synchronize(diskInfoProviderDiskInfoProvider,podFuncActivePodsFunc)[]*v1.Pod{// 省略其他逻辑...// 根据 thresholdToReclaim.Signal 信号进行垃圾回收,如果回收后剩余资源低于阈值,就直接返回 nil,// 代表本次不需要驱逐任何 Pod 了ifm.reclaimNodeLevelResources(ctx,thresholdToReclaim.Signal,resourceToReclaim){klog.InfoS("Eviction manager: able to reduce resource pressure without evicting pods.","resourceName",resourceToReclaim)returnnil}// 否则就在所有 Pod 里找一个进行驱逐,为了保证稳定性,每轮也只会驱逐一个 Podfori:=rangeactivePods{pod:=activePods[i]gracePeriodOverride:=int64(0)if!isHardEvictionThreshold(thresholdToReclaim){gracePeriodOverride=m.config.MaxPodGracePeriodSeconds}message,annotations:=evictionMessage(resourceToReclaim,pod,statsFunc,thresholds,observations)varcondition*v1.PodConditionifutilfeature.DefaultFeatureGate.Enabled(features.PodDisruptionConditions){condition=&v1.PodCondition{Type:v1.DisruptionTarget,Status:v1.ConditionTrue,Reason:v1.PodReasonTerminationByKubelet,Message:message,}}ifm.evictPod(pod,gracePeriodOverride,message,annotations,condition){metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()return[]*v1.Pod{pod}}}}
在eviction功能的主循环里就会根据对应的驱逐信号,执行对应方法,具体对应关系如下:// buildSignalToNodeReclaimFuncs returns reclaim functions associated with resources.funcbuildSignalToNodeReclaimFuncs(imageGCImageGC,containerGCContainerGC,withImageFsbool)map[evictionapi.Signal]nodeReclaimFuncs{signalToReclaimFunc:=map[evictionapi.Signal]nodeReclaimFuncs{}// usage of an imagefs is optionalifwithImageFs{// with an imagefs, nodefs pressure should just delete logssignalToReclaimFunc[evictionapi.SignalNodeFsAvailable]=nodeReclaimFuncs{}signalToReclaimFunc[evictionapi.SignalNodeFsInodesFree]=nodeReclaimFuncs{}// with an imagefs, imagefs pressure should delete unused imagessignalToReclaimFunc[evictionapi.SignalImageFsAvailable]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}signalToReclaimFunc[evictionapi.SignalImageFsInodesFree]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}}else{// without an imagefs, nodefs pressure should delete logs, and unused images// since imagefs and nodefs share a common device, they share common reclaim functionssignalToReclaimFunc[evictionapi.SignalNodeFsAvailable]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}signalToReclaimFunc[evictionapi.SignalNodeFsInodesFree]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}signalToReclaimFunc[evictionapi.SignalImageFsAvailable]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}signalToReclaimFunc[evictionapi.SignalImageFsInodesFree]=nodeReclaimFuncs{containerGC.DeleteAllUnusedContainers,imageGC.DeleteUnusedImages}}returnsignalToReclaimFunc}
可以看到,对于不同信号,做的操作无非是执行容器垃圾回收或者镜像垃圾回收两个动作。
3. 容器垃圾回收
整个回收流程分为三个部分:
1)清理可以驱逐的容器
2)清理可以驱逐的 sandbox
3)清理所有 pod 的日志目录
K8s 中一个 Pod 可以有多个 container,同时除了业务 container 之外还会存在一个 sandbox container,因此这里清理的时候也是按照这个顺序在处理。
先清理业务 container,如果 Pod 里都没有业务 container 了,那么这个 sandbox container 也可以清理了,等 sandbox container 都被清理了,那这个 Pod 就算是被清理干净了,最后就是清理 Pod 对应的日志目录。
func(cgc*containerGC)GarbageCollect(ctxcontext.Context,gcPolicykubecontainer.GCPolicy,allSourcesReadybool,evictNonDeletedPodsbool)error{ctx,otelSpan:=cgc.tracer.Start(ctx,"Containers/GarbageCollect")deferotelSpan.End()errors:=[]error{}// Remove evictable containersiferr:=cgc.evictContainers(ctx,gcPolicy,allSourcesReady,evictNonDeletedPods);err!=nil{errors=append(errors,err)}// Remove sandboxes with zero containersiferr:=cgc.evictSandboxes(ctx,evictNonDeletedPods);err!=nil{errors=append(errors,err)}// Remove pod sandbox log directoryiferr:=cgc.evictPodLogsDirectories(ctx,allSourcesReady);err!=nil{errors=append(errors,err)}returnutilerrors.NewAggregate(errors)}
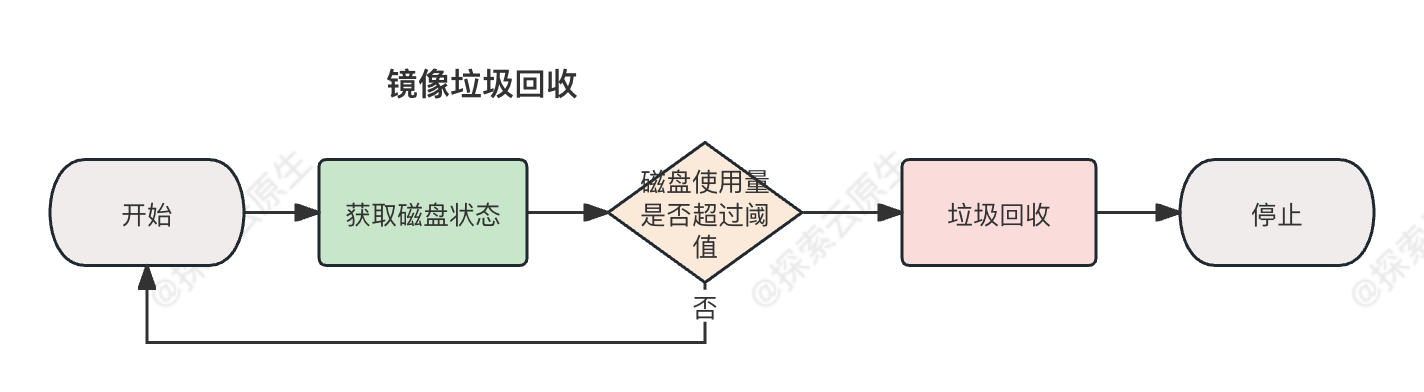
// pkg/kubelet/images/image_gc_manager.go#290func(im*realImageGCManager)GarbageCollect(ctxcontext.Context)error{ctx,otelSpan:=im.tracer.Start(ctx,"Images/GarbageCollect")deferotelSpan.End()// 获取磁盘状态fsStats,err:=im.statsProvider.ImageFsStats(ctx)iferr!=nil{returnerr}// 拿到次哦的容量和可用量varcapacity,availableint64iffsStats.CapacityBytes!=nil{capacity=int64(*fsStats.CapacityBytes)}iffsStats.AvailableBytes!=nil{available=int64(*fsStats.AvailableBytes)}ifavailable>capacity{klog.InfoS("Availability is larger than capacity","available",available,"capacity",capacity)available=capacity}// Check valid capacity.ifcapacity==0{err:=goerrors.New("invalid capacity 0 on image filesystem")im.recorder.Eventf(im.nodeRef,v1.EventTypeWarning,events.InvalidDiskCapacity,err.Error())returnerr}// 计算磁盘使用量,如果超过阈值则进行镜像垃圾回收usagePercent:=100-int(available*100/capacity)ifusagePercent>=im.policy.HighThresholdPercent{// 根据参数计算出需要腾出的空间大小amountToFree:=capacity*int64(100-im.policy.LowThresholdPercent)/100-availableklog.InfoS("Disk usage on image filesystem is over the high threshold, trying to free bytes down to the low threshold","usage",usagePercent,"highThreshold",im.policy.HighThresholdPercent,"amountToFree",amountToFree,"lowThreshold",im.policy.LowThresholdPercent)// 镜像垃圾回收的真正实现在这里freed,err:=im.freeSpace(ctx,amountToFree,time.Now())iferr!=nil{returnerr}// 如果最终腾出的空间小于目标值则记录 event 并返回一个 erriffreed<amountToFree{err:=fmt.Errorf("Failed to garbage collect required amount of images. Attempted to free %d bytes, but only found %d bytes eligible to free.",amountToFree,freed)im.recorder.Eventf(im.nodeRef,v1.EventTypeWarning,events.FreeDiskSpaceFailed,err.Error())returnerr}}returnnil}
func(im*realImageGCManager)Start(){ctx:=context.Background()gowait.Until(func(){// Initial detection make detected time "unknown" in the past.vartstime.Timeifim.initialized{ts=time.Now()}// in first time,ts is zero._,err:=im.detectImages(ctx,ts)iferr!=nil{klog.InfoS("Failed to monitor images","err",err)}else{im.initialized=true}},5*time.Minute,wait.NeverStop)//...
iffreeTime.Sub(image.firstDetected)<im.policy.MinAge{klog.V(5).InfoS("Image ID's age is less than the policy's minAge, not eligible for garbage collection","imageID",image.id,"age",freeTime.Sub(image.firstDetected),"minAge",im.policy.MinAge)continue}