本文主要记录了如何使用 KEDA 对应用进行弹性伸缩,同时分析了 KEDA 工作原理及其大致实现。
1. 什么是 KEDA
KEDA:Kubernetes-based Event Driven Autoscaler.
KEDA是一种基于事件驱动对 K8S 资源对象扩缩容的组件。非常轻量、简单、功能强大,不仅支持基于 CPU / MEM 资源和基于 Cron 定时 HPA 方式,同时也支持各种事件驱动型 HPA,比如 MQ 、Kafka 等消息队列长度事件,Redis 、URL Metric 、Promtheus 数值阀值事件等等事件源(Scalers)。
2. 为什么需要 KEDA
k8s 官方早就推出了 HPA,为什么我们还需要 KEDA 呢?
HPA 在经过三个大版本的演进后当前支持了Resource、Object、External、Pods 等四种类型的指标,演进历程如下:
autoscaling/v1 :只支持基于CPU指标的缩放autoscaling/v2beta1 :支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)的缩放autoscaling/v2beta2 :支持Resource Metrics(资源指标,如pod的CPU)和Custom Metrics(自定义指标)和 ExternalMetrics(额外指标)的缩放。如果需要基于其他地方如 Prometheus、Kafka、云供应商或其他事件上的指标进行伸缩,那么可以通过 v2beta2 版本提供的 external metrics 来实现,具体如下:
1)通过 Prometheus-adaptor 将从 prometheus 中拿到的指标转换为 HPA 能够识别的格式,以此来实现基于 prometheus 指标的弹性伸缩 2)然后应用需要实现 metrics 接口或者对应的 exporter 来将指标暴露给 Prometheus 可以看到, HPA v2beta2 版本就可以实现基于外部指标弹性伸缩,只是实现上比较麻烦,KEDA 的出现主要是为了解决 HPA 无法基于灵活的事件源进行伸缩的这个问题。
毕竟 KEDA 从名字上就体现出了事件驱动。
KEDA 则可以简化这个过程,使用起来更加方便,而且 KEDA 已经内置了几十种常见的 Scaler 可以直接使用。
注意 :KEDA 的出现是为了增强 HPA,而不是替代 HPA。
3. Demo
需要一个 k8s 集群,没有的话可以参考 Kubernetes教程(十一)—使用 KubeClipper 通过一条命令快速创建 k8s 集群 快速创建一个。
KEDA 安装
这里使用 Helm 安装
1
2
3
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace --version v2.9
默认会安装最新版本,对 k8s 版本有要求,当前最新 2.10 需要 k8s 1.24,这边 k8s 是 1.23.6 因此手动安装 KEDA 2.9 版本。
安装完成后会启动两个 pod,能正常启动则算是安装成功。
1
2
3
4
[ root@mcs-1 ~] # kubectl -n keda get po
NAME READY STATUS RESTARTS AGE
keda-operator-94b754f55-4tzqm 1/1 Running 0 21m
keda-operator-metrics-apiserver-655d49f694-7wsww 1/1 Running 0 21m
metrics-server
由于 KEDA 也需要 HPA 配合使用,因此需要安装 metrics-server。
apply 以下 yaml 即可完成 metrics-server 部署
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
cat > metrics-server.yaml << EOF
apiVersion : v1
kind : ServiceAccount
metadata :
labels :
k8s-app : metrics-server
name : metrics-server
namespace : kube-system
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
labels :
k8s-app : metrics-server
rbac.authorization.k8s.io/aggregate-to-admin : "true"
rbac.authorization.k8s.io/aggregate-to-edit : "true"
rbac.authorization.k8s.io/aggregate-to-view : "true"
name : system:aggregated-metrics-reader
rules :
apiGroups :
- metrics.k8s.io
resources :
- pods
- nodes
verbs :
- get
- list
- watch
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
labels :
k8s-app : metrics-server
name : system:metrics-server
rules :
apiGroups :
- ""
resources :
- nodes/metrics
verbs :
- get
apiGroups :
- ""
resources :
- pods
- nodes
verbs :
- get
- list
- watch
---
apiVersion : rbac.authorization.k8s.io/v1
kind : RoleBinding
metadata :
labels :
k8s-app : metrics-server
name : metrics-server-auth-reader
namespace : kube-system
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : Role
name : extension-apiserver-authentication-reader
subjects :
kind : ServiceAccount
name : metrics-server
namespace : kube-system
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
labels :
k8s-app : metrics-server
name : metrics-server:system:auth-delegator
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : ClusterRole
name : system:auth-delegator
subjects :
kind : ServiceAccount
name : metrics-server
namespace : kube-system
---
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRoleBinding
metadata :
labels :
k8s-app : metrics-server
name : system:metrics-server
roleRef :
apiGroup : rbac.authorization.k8s.io
kind : ClusterRole
name : system:metrics-server
subjects :
kind : ServiceAccount
name : metrics-server
namespace : kube-system
---
apiVersion : v1
kind : Service
metadata :
labels :
k8s-app : metrics-server
name : metrics-server
namespace : kube-system
spec :
ports :
- name : https
port : 443
protocol : TCP
targetPort : https
selector :
k8s-app : metrics-server
---
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
k8s-app : metrics-server
name : metrics-server
namespace : kube-system
spec :
selector :
matchLabels :
k8s-app : metrics-server
strategy :
rollingUpdate :
maxUnavailable : 0
template :
metadata :
labels :
k8s-app : metrics-server
spec :
containers :
- args :
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image : dyrnq/metrics-server:v0.6.1
imagePullPolicy : IfNotPresent
livenessProbe :
failureThreshold : 3
httpGet :
path : /livez
port : https
scheme : HTTPS
periodSeconds : 10
name : metrics-server
ports :
- containerPort : 4443
name : https
protocol : TCP
readinessProbe :
failureThreshold : 3
httpGet :
path : /readyz
port : https
scheme : HTTPS
initialDelaySeconds : 20
periodSeconds : 10
resources :
requests :
cpu : 100m
memory : 200Mi
securityContext :
allowPrivilegeEscalation : false
readOnlyRootFilesystem : true
runAsNonRoot : true
runAsUser : 1000
volumeMounts :
- mountPath : /tmp
name : tmp-dir
nodeSelector :
kubernetes.io/os : linux
priorityClassName : system-cluster-critical
serviceAccountName : metrics-server
volumes :
- emptyDir : {}
name : tmp-dir
---
apiVersion : apiregistration.k8s.io/v1
kind : APIService
metadata :
labels :
k8s-app : metrics-server
name : v1beta1.metrics.k8s.io
spec :
group : metrics.k8s.io
groupPriorityMinimum : 100
insecureSkipTLSVerify : true
service :
name : metrics-server
namespace : kube-system
version : v1beta1
versionPriority : 10
EOF
1
kubectl apply -f metrics-server.yaml
测试使用正常运行
1
2
3
[ root@demo ~] # kubectl top node
NAME CPU( cores) CPU% MEMORY( bytes) MEMORY%
demo 585m 14% 4757Mi 60%
基于 CPU 使用率进行弹性伸缩
Deployment
部署一个 php-apache 服务作为工作负载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
cat > deploy.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: deis/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 100m
requests:
cpu: 20m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
EOF
1
kubectl apply -f deploy.yaml
ScaledObject
检测 cpu 压力进行扩缩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
cat > so.yaml <<EOF
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cpu
namespace: default
spec:
scaleTargetRef:
name: php-apache
apiVersion: apps/v1
kind: Deployment
triggers:
- type: cpu
metadata:
type: Utilization
value: "50"
EOF
1
kubectl apply -f so.yaml
测试扩缩容
开始请求,增加压力
1
2
clusterIP = $( kubectl get svc php-apache -o jsonpath = '{.spec.clusterIP}' )
while sleep 0.01; do wget -q -O- http://$clusterIP ; done
过一会就能看到 pod 数在增加
1
2
3
4
5
6
7
8
9
[ root@mcs-1 keda] # kubectl get po
NAME READY STATUS RESTARTS AGE
php-apache-95cc776df-5grp6 1/1 Running 0 2m52s
php-apache-95cc776df-85jpd 1/1 Running 0 33s
php-apache-95cc776df-cxdlr 1/1 Running 0 48s
php-apache-95cc776df-gr4nh 1/1 Running 0 33s
php-apache-95cc776df-hs5xs 1/1 Running 0 48s
php-apache-95cc776df-jrt7h 1/1 Running 0 48s
php-apache-95cc776df-sddpq 1/1 Running 0 33s
实际上并不是 KEDA 直接调整了 pod 的数量,KEDA 只是创建了一个 HPA 对象出来
相关日志如下
1
2
3
[ root@test ~] #kubectl -n keda logs -f keda-operator-94b754f55-4tzqm
2023-05-15T08:53:57Z INFO Creating a new HPA { "controller" : "scaledobject" , "controllerGroup" : "keda.sh" , "controllerKind" : "ScaledObject" , "ScaledObject" : { "name" :"cpu" ,"namespace" :"default" } , "namespace" : "default" , "name" : "cpu" , "reconcileID" : "8bd04ba9-f100-49c1-9f28-ae28e55ae9eb" , "HPA.Namespace" : "default" , "HPA.Name" : "keda-hpa-cpu" }
2023-05-15T08:53:57Z INFO cpu_memory_scaler trigger.metadata.type is deprecated in favor of trigger.metricType { "type" : "ScaledObject" , "namespace" : "default" , "name" : "cpu" }
查看创建出来的 HPA
1
2
3
[ root@mcs-1 ~] # kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-cpu Deployment/php-apache 151%/50% 1 100 6 37m
然后停止请求,等压力下降后,hpa 会自动将 pod 数进行回收。
1
2
3
4
5
6
[ root@mcs-1 ~] # kubectl get po
NAME READY STATUS RESTARTS AGE
php-apache-57fcc894d5-6ssc7 1/1 Running 0 78m
[ root@mcs-1 ~] # kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-cpu Deployment/php-apache 0%/50% 1 100 1 65m
基于Kafka 消息数进行弹性伸缩
上一个 Demo 非常简单,其实直接用 HPA 也能实现,并不能完全体现出 KEDA 的作用。
假设,现在我们有这么一个场景,运行的业务是生产者消费者模型,消费者从 Kafka 里拿消息进行消费,然后我们希望根据 Kafka 里堆积的消息数来对消费者 做一个弹性伸缩 。
这种场景下再基于 CPU 进行扩缩容可能就不够准确了,而直接基于堆积的消息数来扩缩容可能是最好的选择。
如果使用 HPA 的话也可以实现,但是很麻烦,而 KEDA 则非常简单了,KEDA 内置了 kakfa scaler ,直接使用即可。
KEDA 的 kafka scaler 工作流程如下:
当没有待处理的消息时,KEDA 可以根据 minReplica 集将部署缩放到 0 或 1。 当消息到达时,KEDA 会检测到此事件并激活部署。 当部署开始运行时,其中一个容器连接到 Kafka 并开始拉取消息。 随着越来越多的消息到达 Kafka Topic,KEDA 可以将这些数据提供给 HPA 以推动横向扩展。 当消息被消费完之后,KEDA 可以根据 minReplica 集将部署缩放到 0 或 1。 使用起来也非常简单,只需要将 ScaledObject 中的 triggers 字段修改一下即可,具体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
triggers :
type : kafka
metadata :
bootstrapServers : kafka.svc:9092
consumerGroup : my-group
topic : test-topic
lagThreshold : '100'
activationLagThreshold : '3'
offsetResetPolicy : latest
allowIdleConsumers : false
scaleToZeroOnInvalidOffset : false
excludePersistentLag : false
version : 1.0.0
partitionLimitation : '1,2,10-20,31'
tls : enable
sasl : plaintext
暂时关注前面几个参数即可:
其中 bootstrapServers、consumerGroup、topic 都是 kafka 信息 lagThreshold 则是扩容的阈值,当消息延迟大于这个阈值时就会对 deployment 进行扩容。 配置后,keda 内置的 kafka scaler 就会根据提供的 auth 信息访问 kafka,拿到指定 topic 中的消息堆积数量,然后根据 lagThreshold 值计算出需要扩容的应用副本数。
这里有一个 Kafka-go 的教程:kafka-go-example
4. KEDA 是怎么工作的
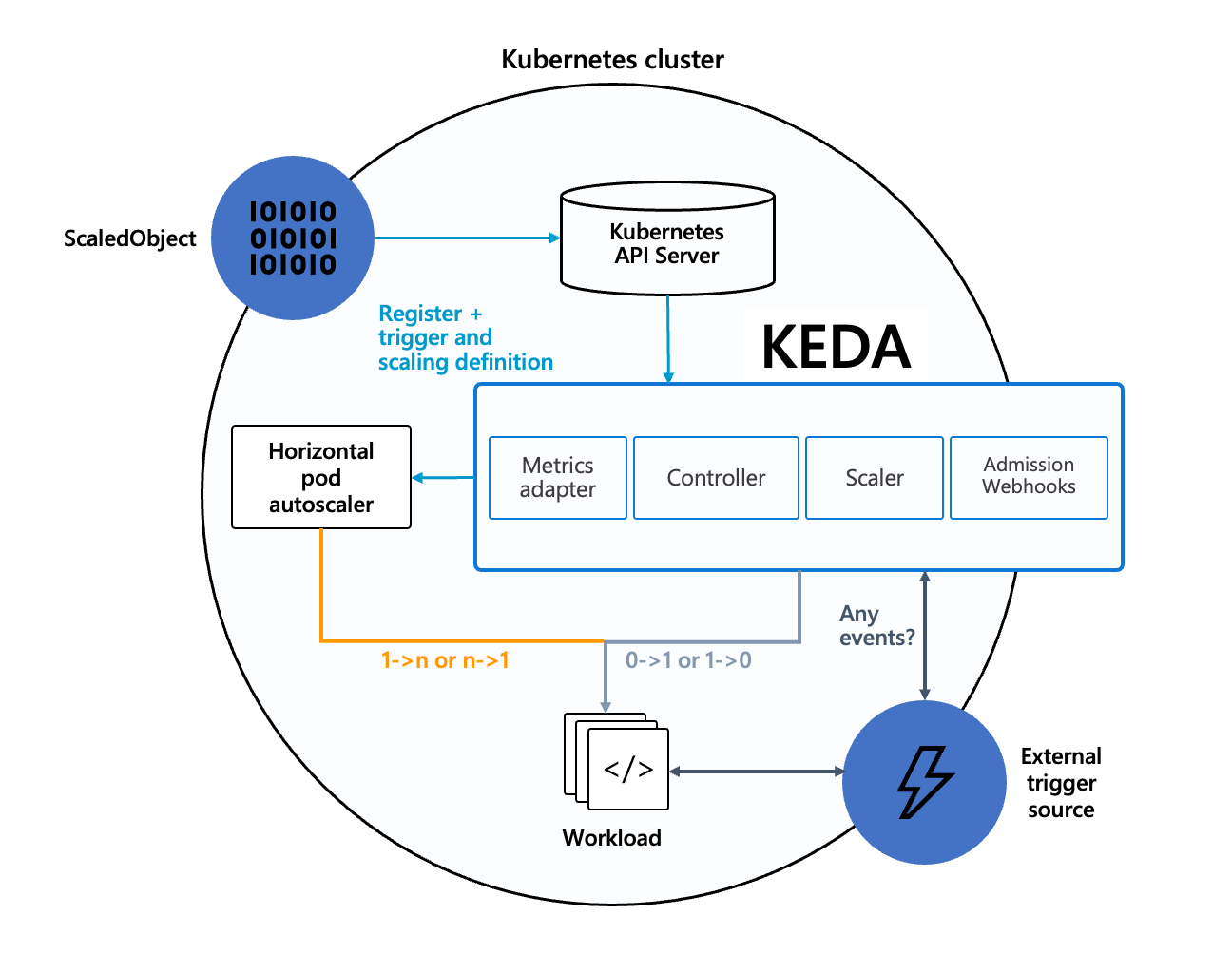
架构
KEDA 由以下组件组成:
Scaler:连接到外部组件(例如 Prometheus 或者 RabbitMQ) 并获取指标(例如,待处理消息队列大小) )获取指标 Metrics Adapter: 将 Scaler 获取的指标转化成 HPA 可以使用的格式并传递给 HPA Controller:负责创建和更新一个 HPA 对象,并负责扩缩到零 keda operator:负责创建维护 HPA 对象资源,同时激活和停止 HPA 伸缩。在无事件的时候将副本数降低为 0 (如果未设置 minReplicaCount 的话) metrics server: 实现了 HPA 中 external metrics,根据事件源配置返回计算结果。 HPA 控制了副本 1->N 和 N->1 的变化。keda 控制了副本 0->1 和 1->0 的变化(起到了激活和停止的作用,对于一些消费型的任务副本比较有用,比如在凌晨启动任务进行消费)
工作流程
KEDA 工作流程如下:
KEDA 主要工作分为两个部分:
1)根据 ScaledObject 对象动态创建并维护一个 HPA 对象以及动态更新 External Metrics 服务里的 http handler 2)提供 Scaler,处理由 External Metrics 服务转发过来的指标查询请求,并真正的查询外部系统拿到指标比如指标名为 queueLen 即队列长度,然后 Scaler type 为 kafaka,那么这个 Scaler 可能需要用户提供 kafka endpoint 及认证信息,然后 Scaler 在收到请求时就要根据 ScaledObject name + namespace 拿到 ScaledObject,并提取到相关信息,最终请求 kafka 拿到队列长度返回。 首先创建 ScaledObject 对象,里面会指定 scaler 的类型以及一些访问凭证,例如:下面这个 ScaledObject 就指定了一个 prometheus 类型的 scaler,同时通过 serverAddress 字段指定了 prometheus 的访问地址。
在具体的 scaler 逻辑里,就可以根据这 url 去访问 prometheus 了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
cat > so-prom.yaml << EOF
apiVersion : keda.sh/v1alpha1
kind : ScaledObject
metadata :
name : prometheus-core
spec :
scaleTargetRef :
name : php-apache
apiVersion : apps/v1
kind : Deployment
triggers :
- type : prometheus
metadata :
metricName : machine_cpu_cores
serverAddress : http://prometheus-service.monitoring:8080
threshold : '4'
query : machine_cpu_cores
EOF
ScaledObject 对象创建之后 KEDA 会做两件事情:
1)根据 ScaledObject 对象中的信息创建一个 HPA 对象 2)根据 triggers 里指定的信息,注册一个 External metrics 到 k8s apiserver 具体如下,可以看到创建了一个 HPA 对象
1
2
3
[ root@keda ~] # kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-prometheus-core Deployment/php-apache 4/4 ( avg) 1 100 1 41m
HPA 内容如下
省略其他内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
spec :
maxReplicas : 100
metrics :
- external :
metric :
name : s0-prometheus-machine_cpu_cores
selector :
matchLabels :
scaledobject.keda.sh/name : prometheus-core
target :
averageValue : "4"
type : AverageValue
type : External
minReplicas : 1
scaleTargetRef :
apiVersion : apps/v1
kind : Deployment
name : php-apache
可以看到,所有内容都来源于前面的 ScaledObject 对象。
同时还会注册一个 external metrics 对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
[ root@keda ~] # kubectl get apiservices | grep external.metrics.k8s.io
v1beta1.external.metrics.k8s.io keda/keda-operator-metrics-apiserver True 123m
[ root@keda ~] # kubectl get apiservice v1beta1.external.metrics.k8s.io -oyaml
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
annotations:
meta.helm.sh/release-name: keda
meta.helm.sh/release-namespace: keda
creationTimestamp: "2023-05-17T08:13:18Z"
labels:
app.kubernetes.io/component: operator
app.kubernetes.io/instance: keda
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: v1beta1.external.metrics.k8s.io
app.kubernetes.io/part-of: keda-operator
app.kubernetes.io/version: 2.9.3
helm.sh/chart: keda-2.9.4
name: v1beta1.external.metrics.k8s.io
resourceVersion: "9353"
uid: 5981633e-3e8a-437f-8b01-533a7ae50502
spec:
group: external.metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: keda-operator-metrics-apiserver
namespace: keda
port: 443
version: v1beta1
versionPriority: 100
status:
conditions:
- lastTransitionTime: "2023-05-17T08:33:18Z"
message: all checks passed
reason: Passed
status: "True"
type: Available
访问一下试试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[ root@keda ~] # kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1"|jq .
{
"kind" : "APIResourceList" ,
"apiVersion" : "v1" ,
"groupVersion" : "external.metrics.k8s.io/v1beta1" ,
"resources" : [
{
"name" : "s0-prometheus-machine_cpu_cores" ,
"singularName" : "" ,
"namespaced" : true,
"kind" : "ExternalMetricValueList" ,
"verbs" : [
"get"
]
}
]
}
可以看到 resources 里面已经正好就是我们刚才创建的 ScaledObject 对象,访问一下看能拿到具体指标不。
实际上 KEDA 有一个MetricsScaledObjectReconciler 会根据创建的 ScaledObject 对象动态注册 metrics。
具体访问路径见官方文档:keda.sh
语法如下:
1
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/YOUR_NAMESPACE/YOUR_METRIC_NAME?labelSelector=scaledobject.keda.sh%2Fname%3D{SCALED_OBJECT_NAME}"
对于上面的 ScaledObject,请求命令如下:
1
2
3
4
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/s0-prometheus-machine_cpu_cores?labelSelector=scaledobject.keda.sh%2Fname%3Dprometheus-core" | jq .
kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/s0-default-hpa-scale-demo?labelSelector=scaledobject.keda.sh%2Fname%3Dhpa-scale-demo" | jq .
返回结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[ root@keda ~] # kubectl get --raw "/apis/external.metrics.k8s.io/v1beta1/namespaces/default/s0-prometheus-machine_cpu_cores?labelSelector=scaledobject.keda.sh%2Fname%3Dprometheus-core" | jq .
{
"kind" : "ExternalMetricValueList" ,
"apiVersion" : "external.metrics.k8s.io/v1beta1" ,
"metadata" : {} ,
"items" : [
{
"metricName" : "s0-prometheus-machine_cpu_cores" ,
"metricLabels" : null,
"timestamp" : "2023-05-17T10:42:42Z" ,
"value" : "4"
}
]
}
请求过来的时候 keda 会将请求转发到具体的 scaler 里,scaler 就根据参数请求外部系统拿到真正的指标并返回到 HPA,HPA 则根据当前指标和阈值判断扩容。
5. 小结
本文主要演示了 KEDA 的使用,同时也分析了其具体的工作流程。
KEDA 主要是为了解决 HPA 无法基于灵活的外部事件来实现弹性伸缩这个问题。
KEDA 内置了多种 Scaler 以满足不同场景的使用需求,简化了 基于 HPA + Prometheus Adaptor + XXExporter 的自定义流程。
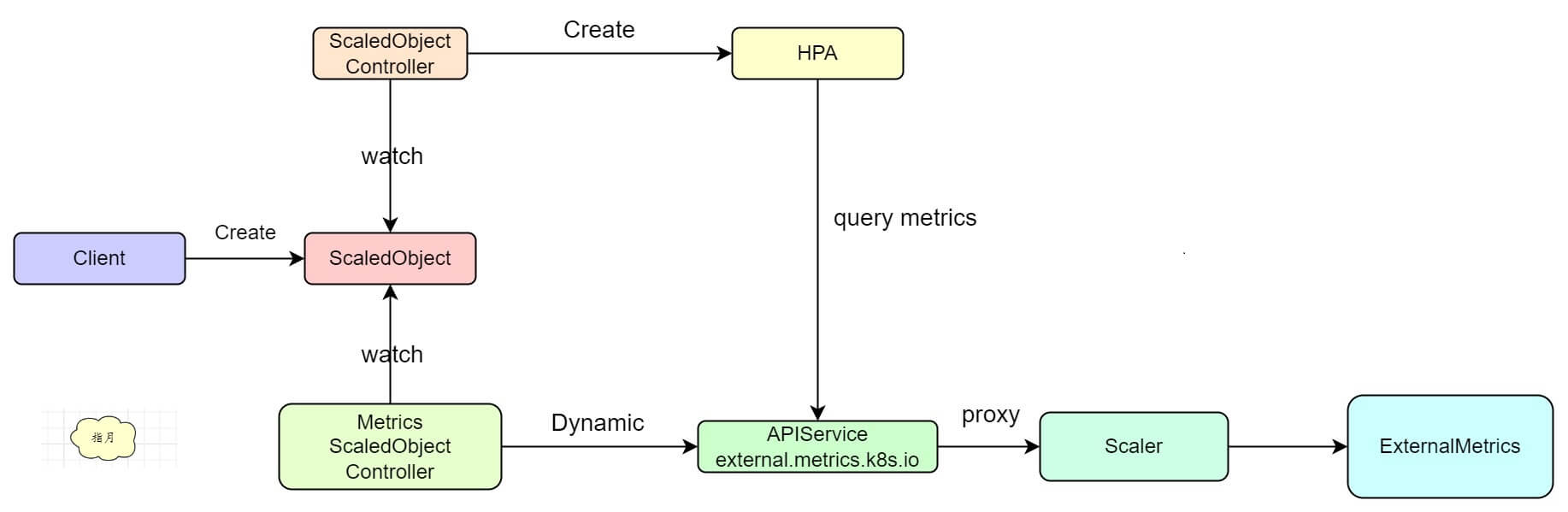
理解 KEDA 的工作流程之后就会比较清晰了,再贴一下这个图
在创建一个 ScalerObject 之后, KEDA controller 就会动态注册一个 handler 到 external.metrics.k8s.io 这个服务上,最终 HPA 请求指标时则会根据路由转发到具体的 Scaler 上,Scaler 再根据 ScalerObject 中的配置请求外部系统拿到数据并将其转换为 HPA 能够识别的格式,最终返回给 HPA。