$ sudo ip netns add ns1
$ sudo ip netns add ns2
$ sudo ip netns show
ns2
ns1
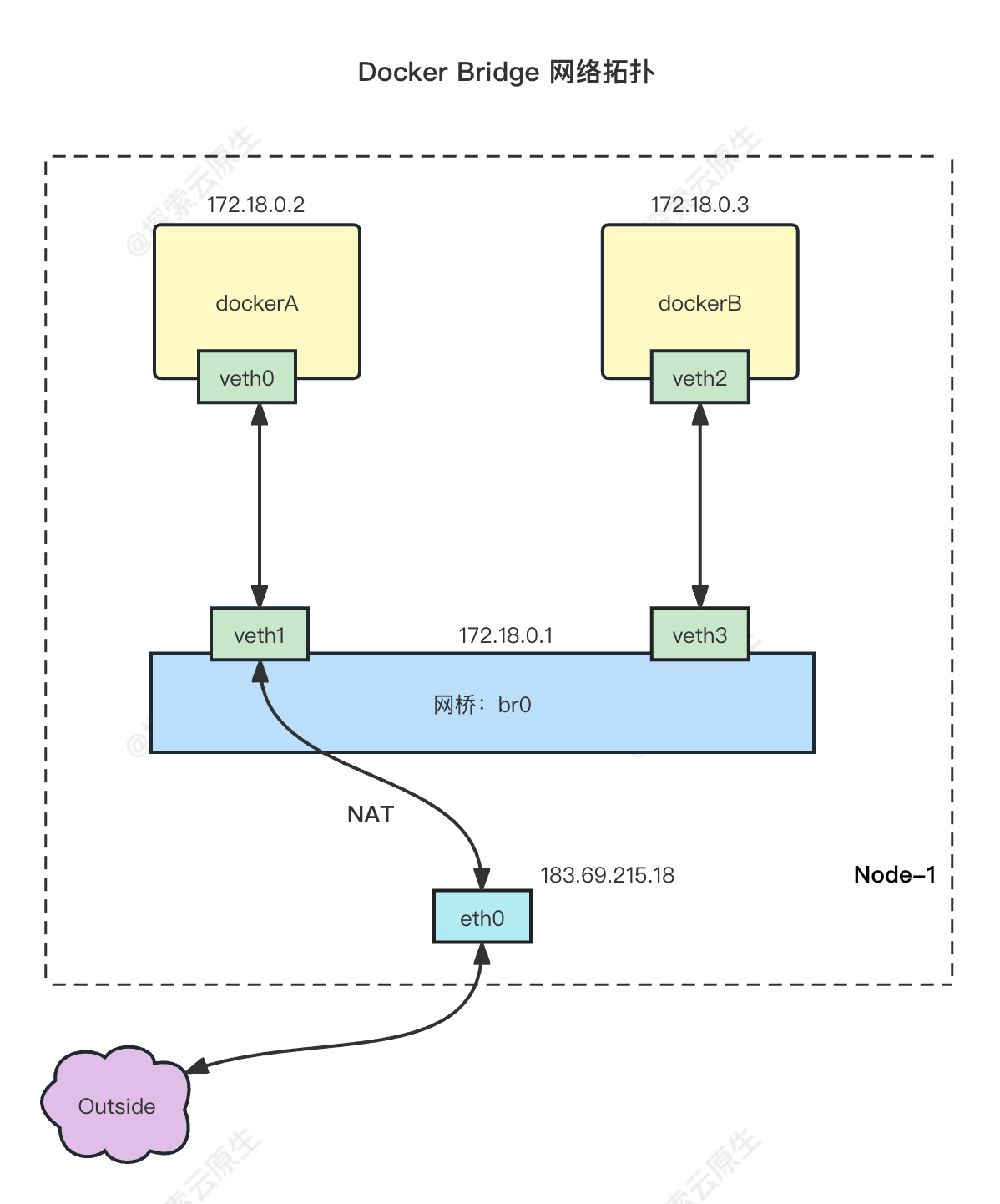
创建 Veth pairs
1
2
sudo ip link add veth0 type veth peer name veth1
sudo ip link add veth2 type veth peer name veth3
查看一下:
1
2
3
4
5
6
7
8
9
10
11
12
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether fa:16:3e:9b:9b:33 brd ff:ff:ff:ff:ff:ff
3: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 9a:45:4c:f9:77:eb brd ff:ff:ff:ff:ff:ff
4: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fe:5a:a1:3b:94:9b brd ff:ff:ff:ff:ff:ff
5: veth3@veth2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 96:d2:e4:ea:9a:1d brd ff:ff:ff:ff:ff:ff
6: veth2@veth3: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
将 Veth 的一端放入“容器”
将 veth 的一端移动到对应的 Namespace 就相当于把这张网卡加入到’容器‘里了。
1
2
sudo ip link set veth0 netns ns1
sudo ip link set veth2 netns ns2
查看宿主机上的网卡
1
2
3
4
5
6
7
8
9
$ ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether fa:16:3e:9b:9b:33 brd ff:ff:ff:ff:ff:ff
3: veth1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 9a:45:4c:f9:77:eb brd ff:ff:ff:ff:ff:ff link-netns ns1
5: veth3@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 96:d2:e4:ea:9a:1d brd ff:ff:ff:ff:ff:ff link-netns ns2
发现少了两个,然后进入容器对应Namespace查看一下容器中的网卡:
1
2
3
4
5
6
7
8
9
10
$ sudo ip netns exec ns1 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether fe:5a:a1:3b:94:9b brd ff:ff:ff:ff:ff:ff link-netnsid 0$ sudo ip netns exec ns2 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: veth2@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 8e:6a:e4:a0:50:ce brd ff:ff:ff:ff:ff:ff link-netnsid 0
$ sudo ip netns exec ns1 ping -c 3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1ttl=80time=21.1 ms
64 bytes from 114.114.114.114: icmp_seq=2ttl=89time=19.5 ms
64 bytes from 114.114.114.114: icmp_seq=3ttl=86time=19.2 ms