探索 Easy Dataset:高效构建大模型训练数据的全流程指南

在大模型时代,高质量训练数据的重要性不言而喻。本文全面介绍了 Easy Dataset 这一强大工具,它能帮助开发者和数据科学家从各种文档中快速构建结构化的问答数据集,大幅简化大模型训练数据的准备过程。
Easy Dataset 是一个强大的大模型数据集创建工具,有以下特点:
智能文档处理:支持 PDF、Markdown、DOCX、TXT 等多种格式智能识别和处理
智能文本分割:支持多种智能文本分割算法、支持自定义可视化分段
智能问题生成:从每个文本片段中提取相关问题
领域标签:为数据集智能构建全局领域标签,具备全局理解能力
答案生成:使用 LLM API 为每个问题生成全面的答案、思维链(COT)
灵活编辑:在流程的任何阶段编辑问题、答案和数据集
多种导出格式:以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集
广泛的模型支持:兼容所有遵循 OpenAI 格式的 LLM API
用户友好界面:为技术和非技术用户设计的直观 UI
自定义系统提示:添加自定义系统提示以引导模型响应
Github 地址:https://github.com/ConardLi/easy-dataset
1. Easy Dataset 部署
这里简单使用 Docker 方式启动。
拉取镜像
| |
部署
| |
访问 17171 端口即可进入 Easy Dataset 界面。
| |
2. 准备工作
在正式生成数据集之前还需要做一点准备工作。
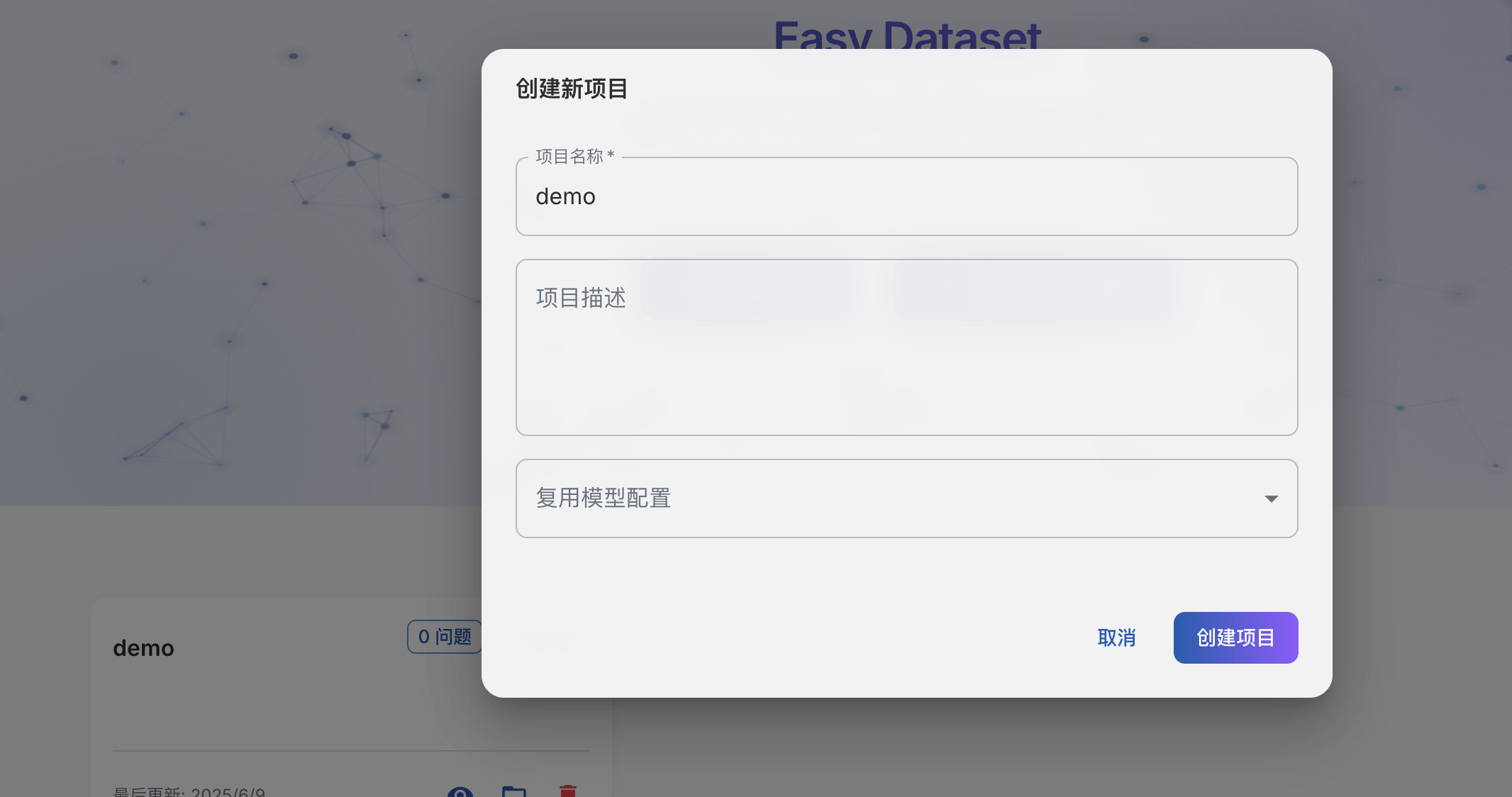
创建项目
EasyDataset 中以项目为单位进行管理,因此进入界面后需要先创建一个项目
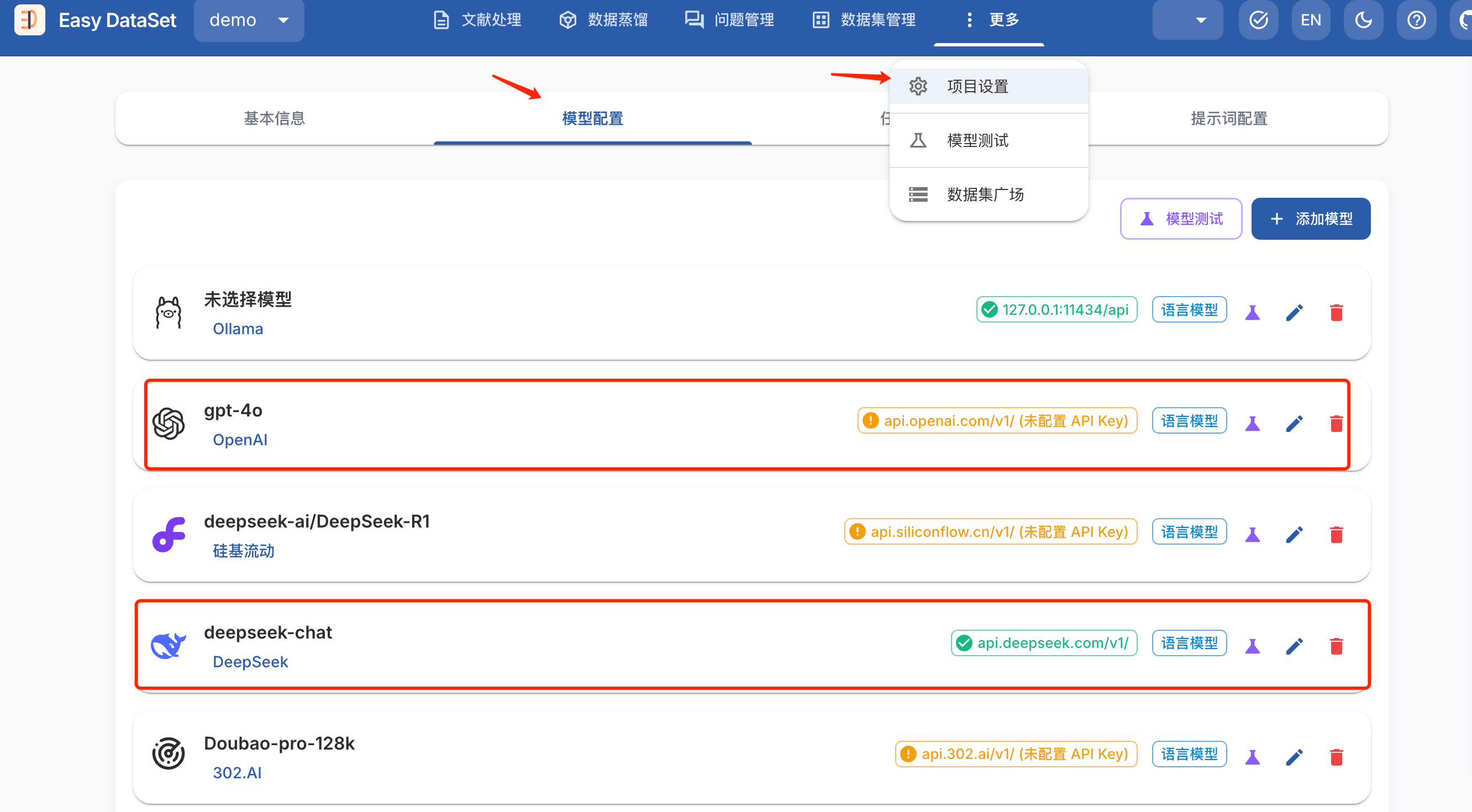
配置模型
项目创建后需要先配置一个模型才能正常使用,更多 -> 项目设置 -> 模型配置
Easy Dataset 支持 OpenAI 标准协议 的模型接入,兼容 Ollama,用户仅需配置 模型名称、API地址、密钥 即可完成适配,内置模型库预填主流厂商端点。
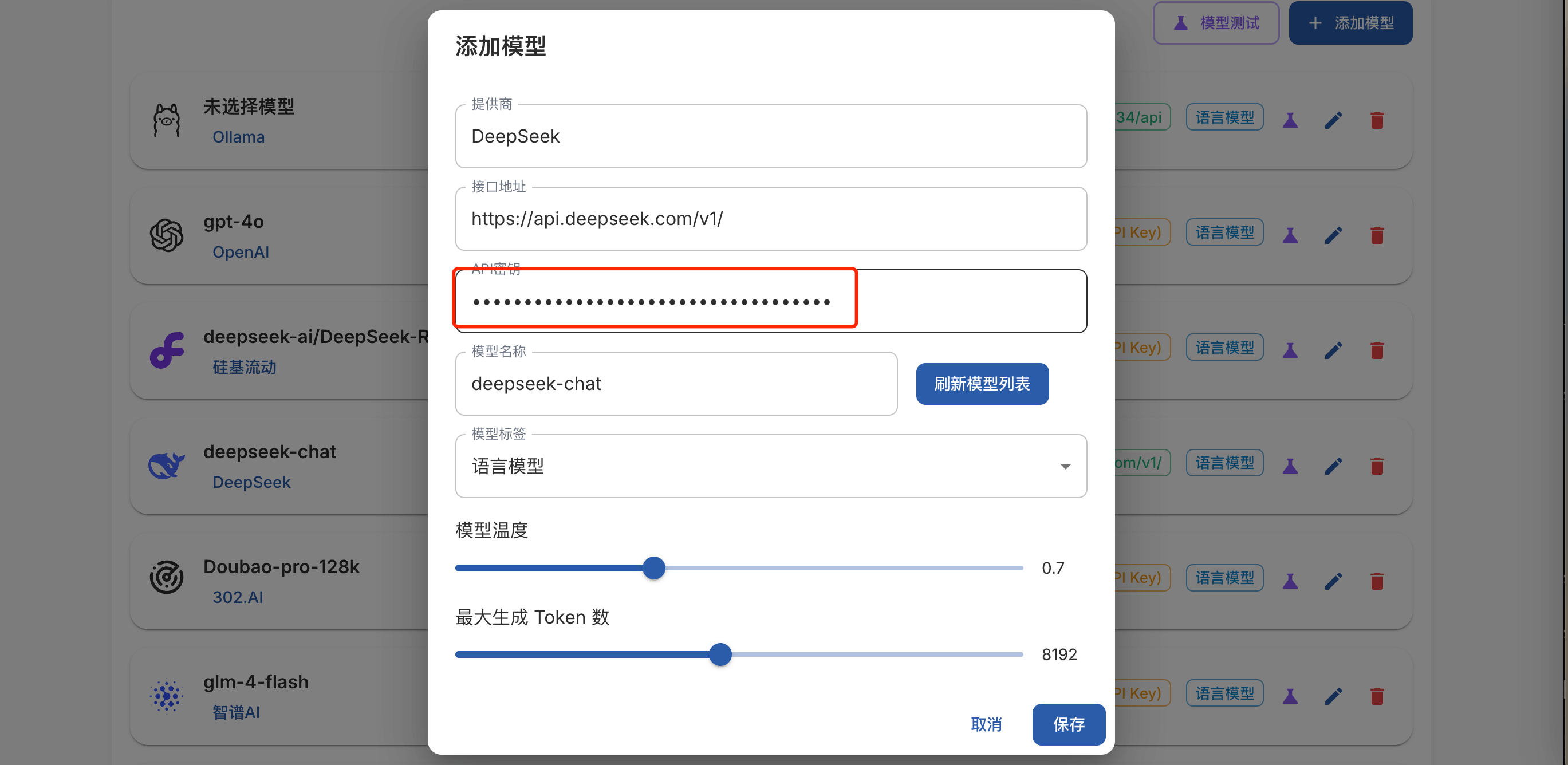
这里我们使用 DeepSeek,只需要填写 API Key 即可
完成后验证一下模型是否可用
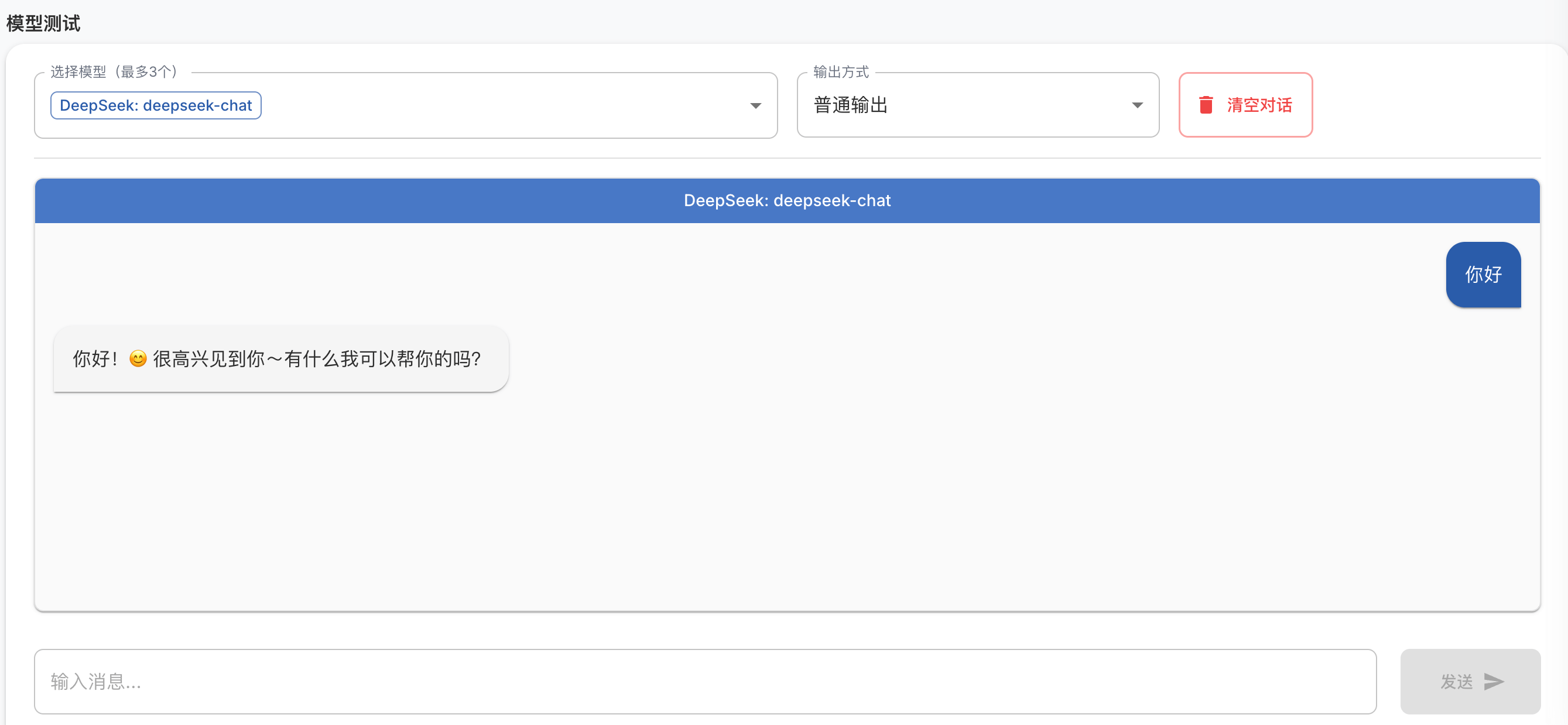
配置好模型之后,就可以开始生成数据集了。
3. 生成数据集
从原始文件到最终的数据集大概分为以下几个步骤:
1)文献处理:支持 Markdown、PDF、World、Excel 等格式文件,将上传的文档智能切分为小的文本块
2)问题生成:利用大模型,从文本块中提取问题
3)构造答案:利用大模型,根据问题以及对应文本块内容信息生成答案
4)导出数据集:以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集
文献处理
Easy Dataset 支持多种类型(PDF、World、Excel)的文档,系统会自动解析并分割文档内容。
这里我们使用一个 PDF 进行测试:
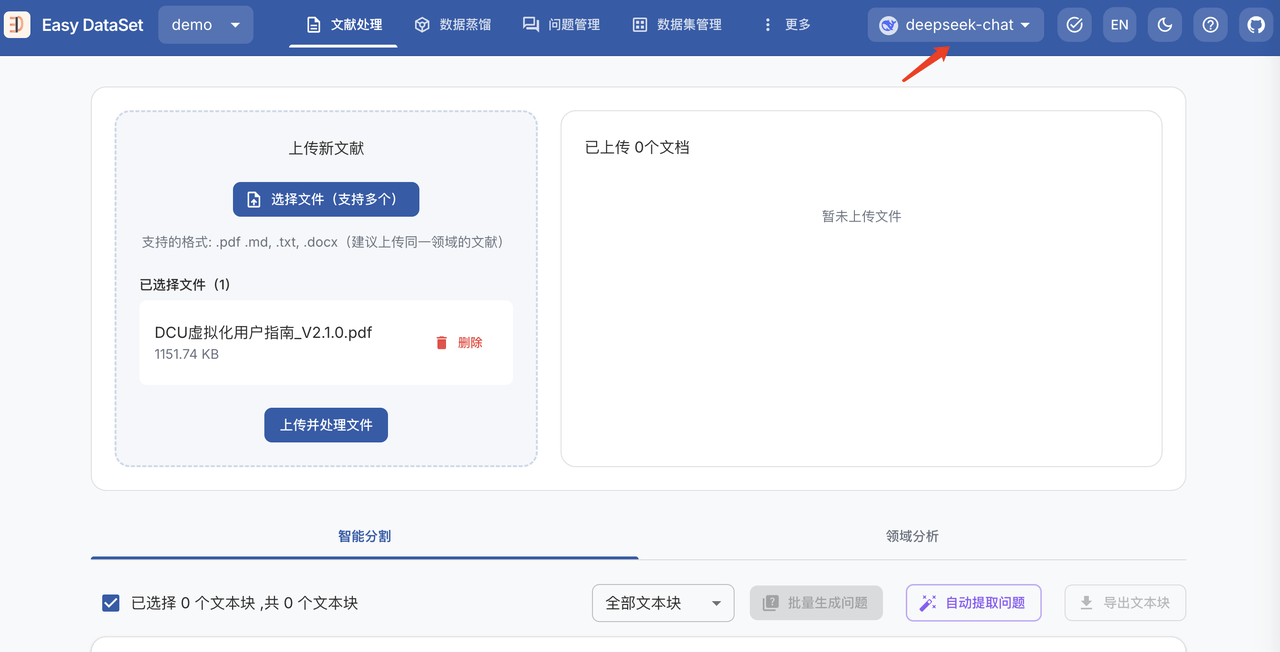
注意:点击上传之前需要先选择模型,如界面右上角所示。
选择好之后点击上传并处理文件,系统就会开始解析并分割文档。
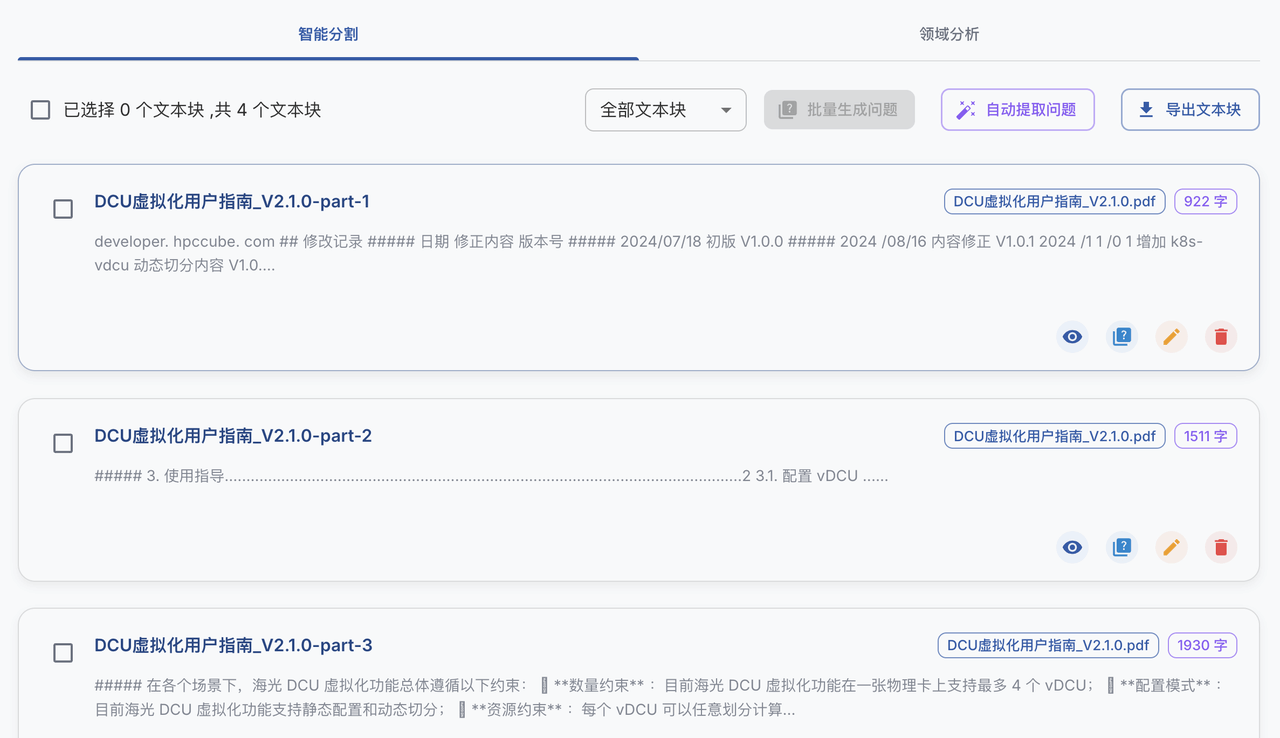
分割后如下:
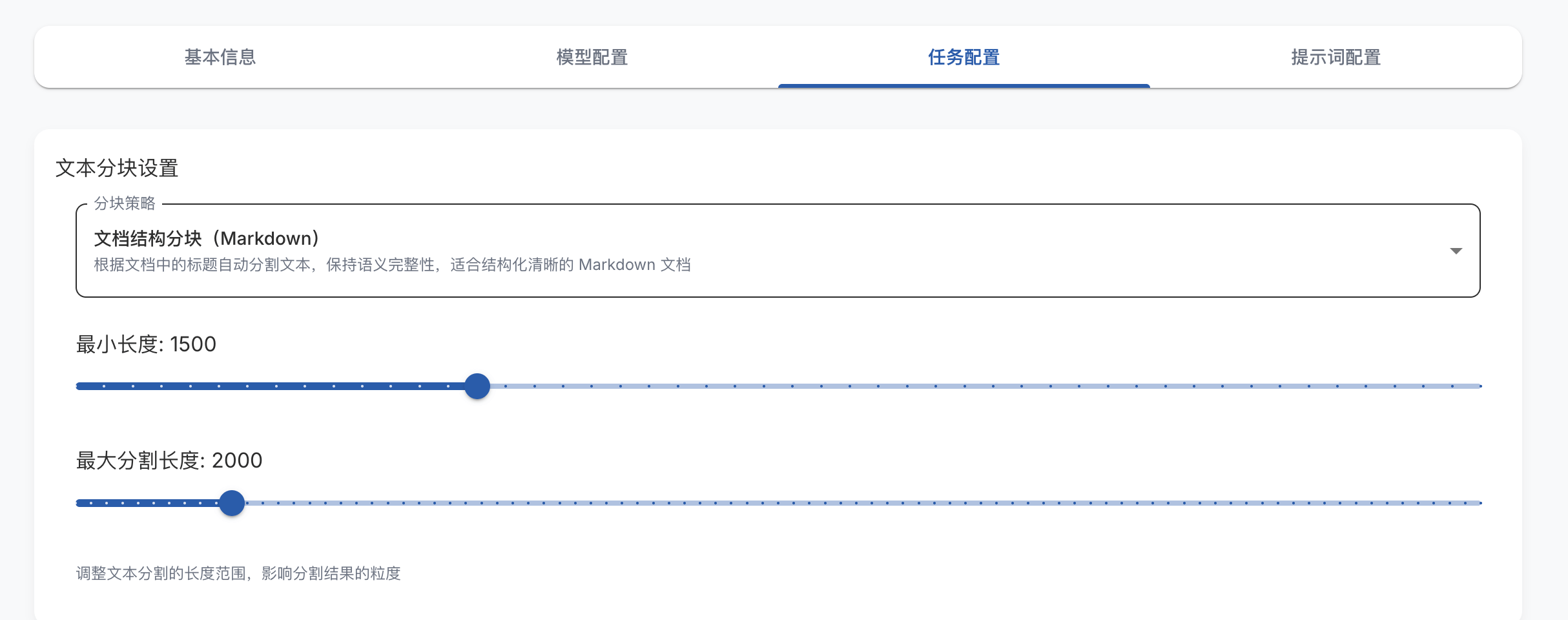
切分参数也可以在 项目设置->任务配置 进行配置
问题生成
接下来则是从分割好的文本块中提取问题,这块会用到配置的大模型来处理。
点击 自动提取问题,系统会后台异步自动查询待生成问题的文本块,并提取问题。
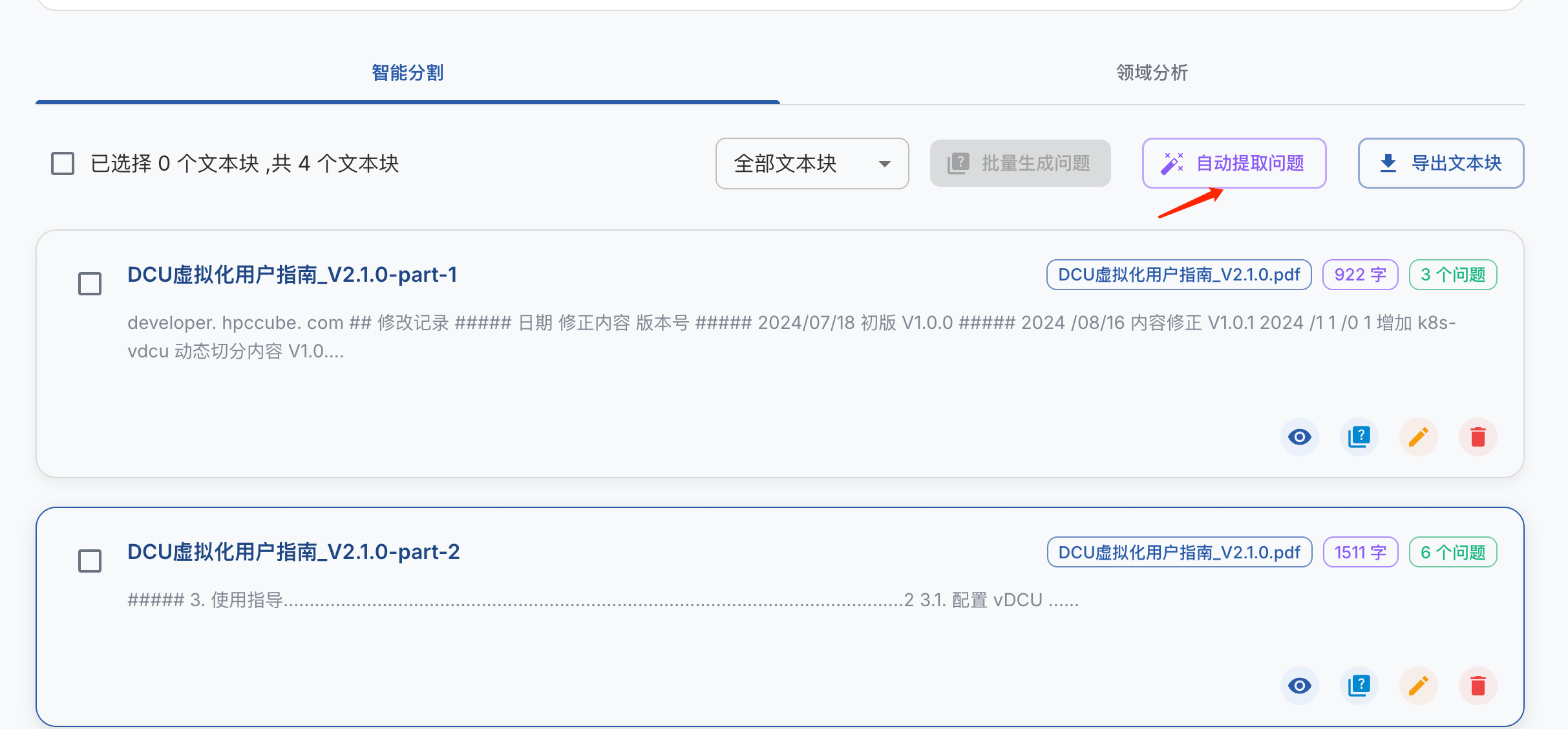
点击后可在任务管理中心可以看到处理进度

跳转到问题管理界面,即可查看本次生成的问题
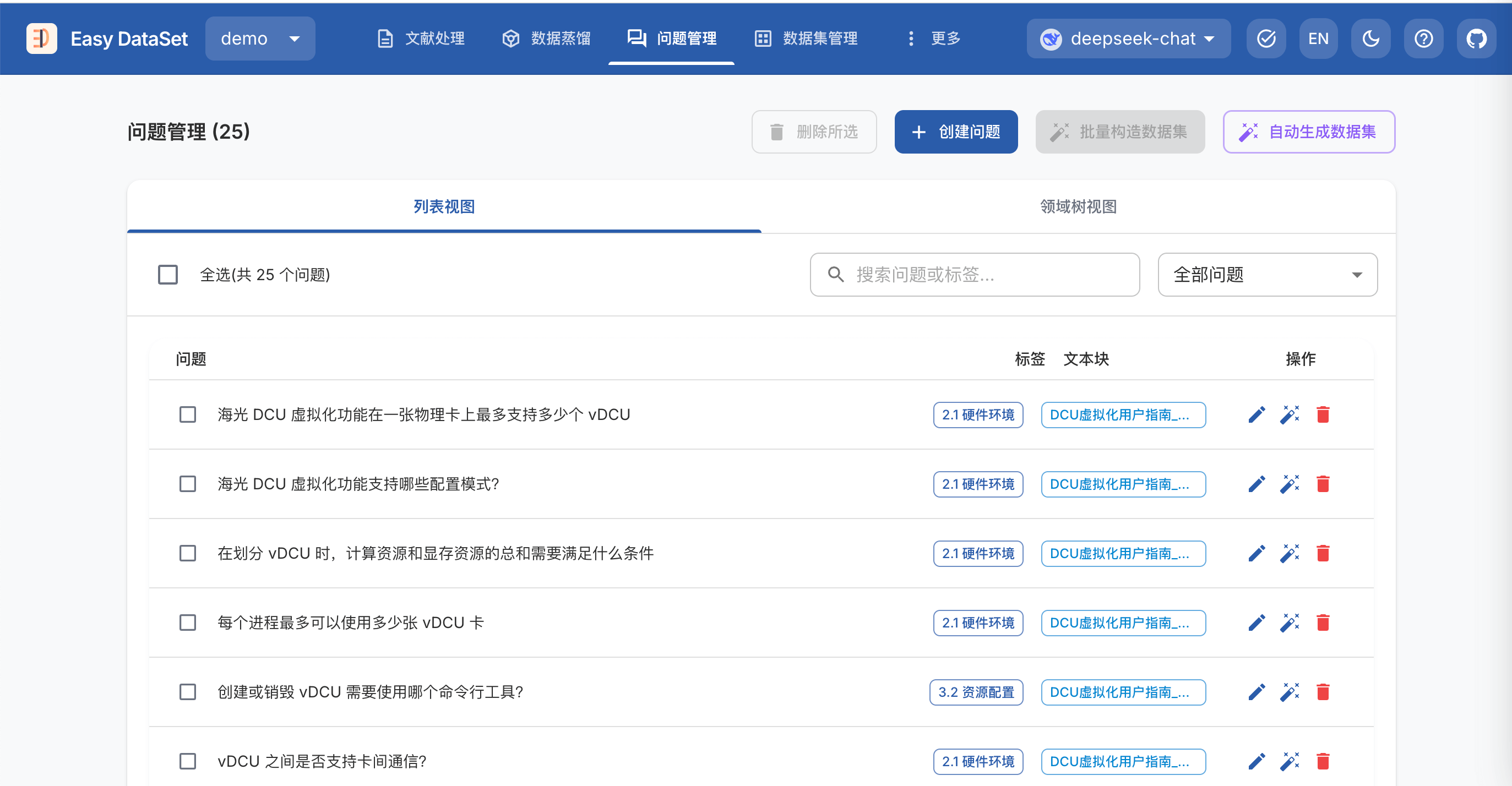
问题生成参数也可以在 项目设置->任务配置 进行配置
答案构建
Easy DataSet 会根据问题 + 问题对应的文本块 + 领域标签来一起生成答案,来保障答案和文献本身的相关性。
同样的,点击 自动生成数据集,Easy Dataset 会自动待生成答案的问题,并为其生成答案。
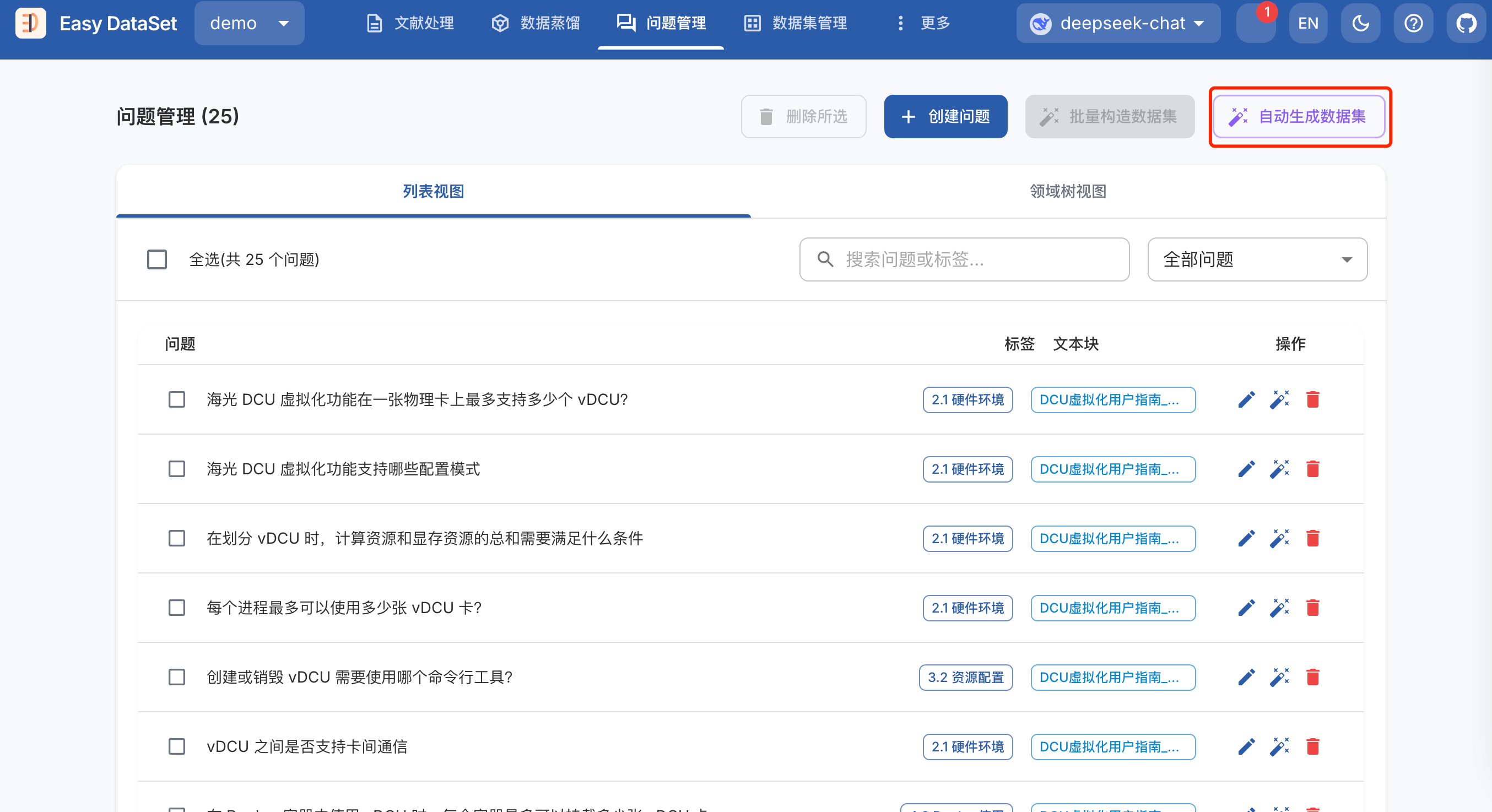
查看任务进度
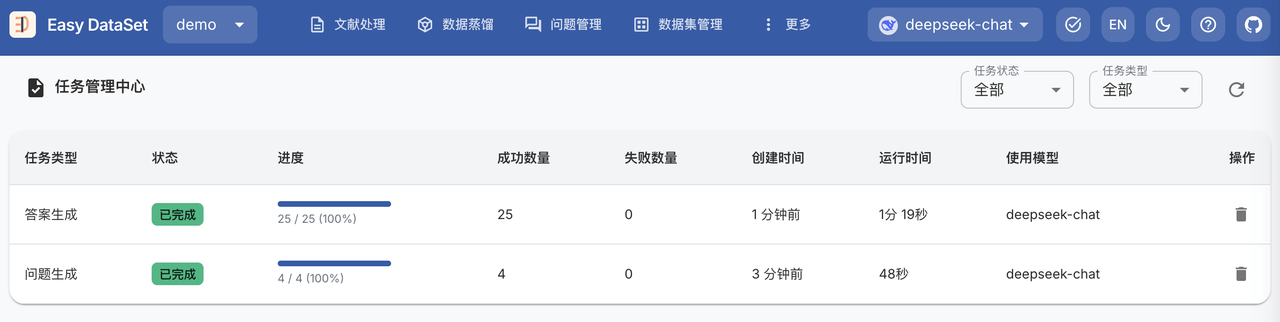
答案生成完成后,就可以在 数据集管理 界面查看生成的数据集了,例如:
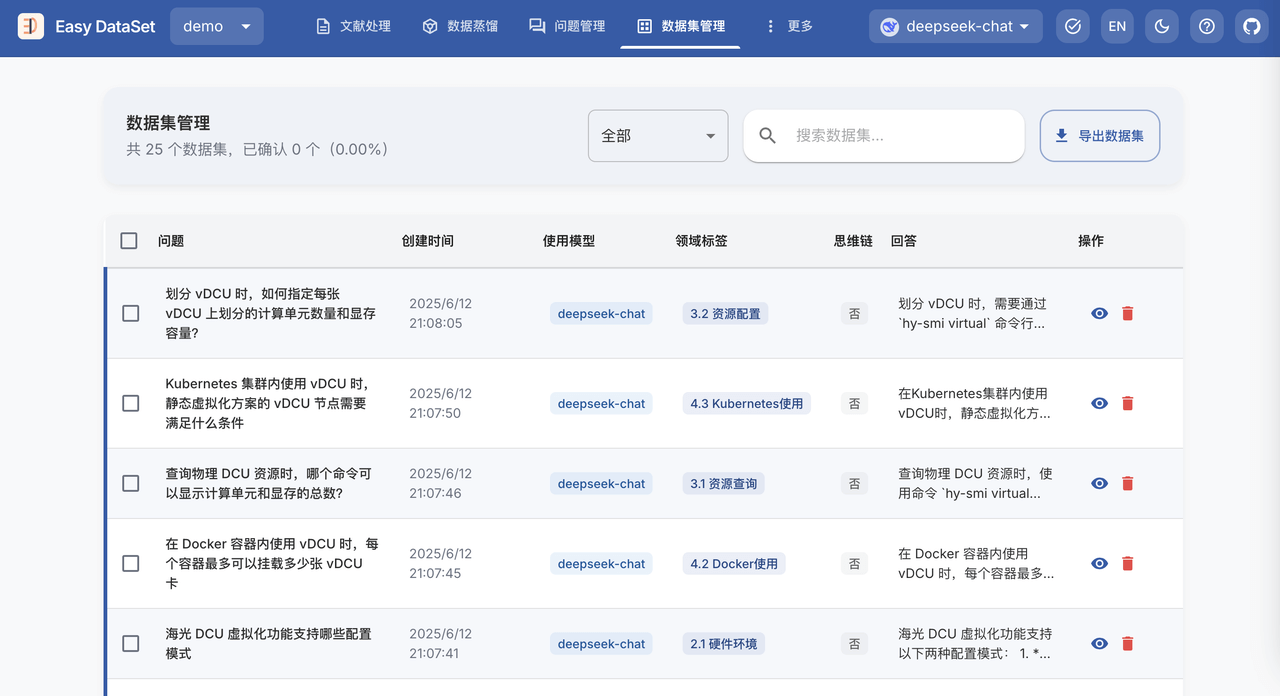
对于不满意的数据集,可以手动修改或者为 AI 提供修改建议,让 AI 进行修改。
修改完成后点击 确认保留 即可将该数据集标记为 已确认。
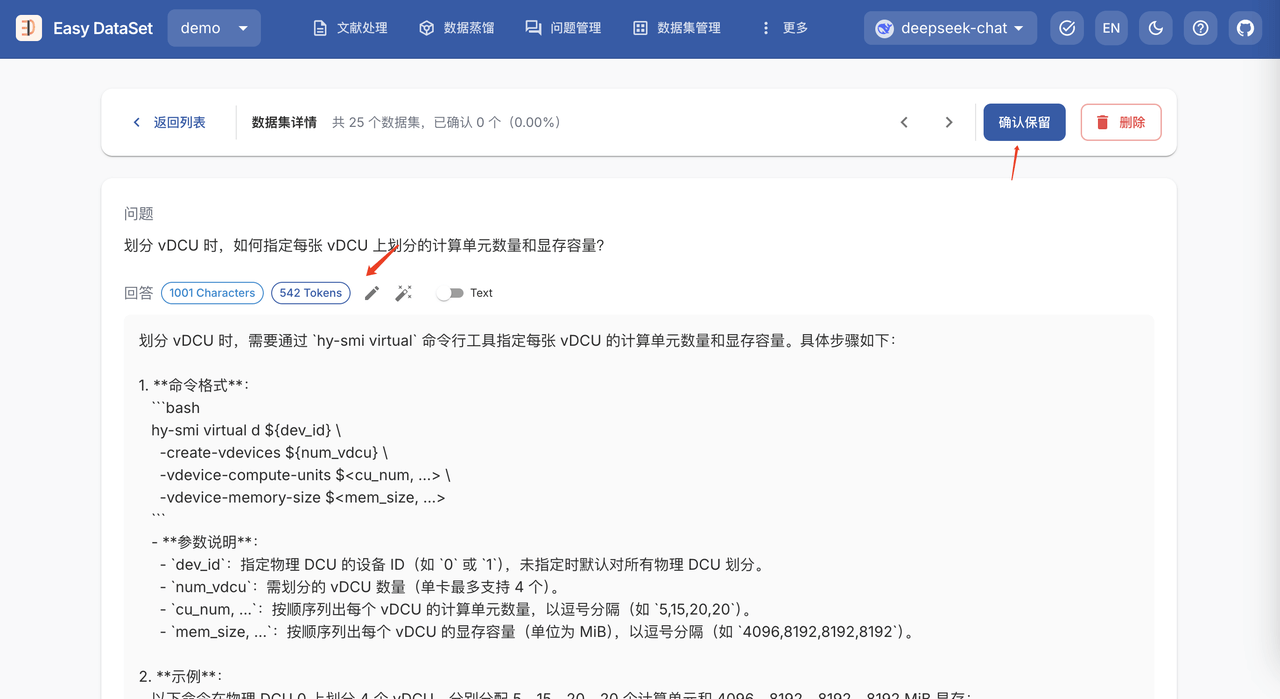
确认数据集操作并不是必须的,仅通过是否含有已确认标签便于进行区分。
导出数据集
数据集处理完成后,即可导出。
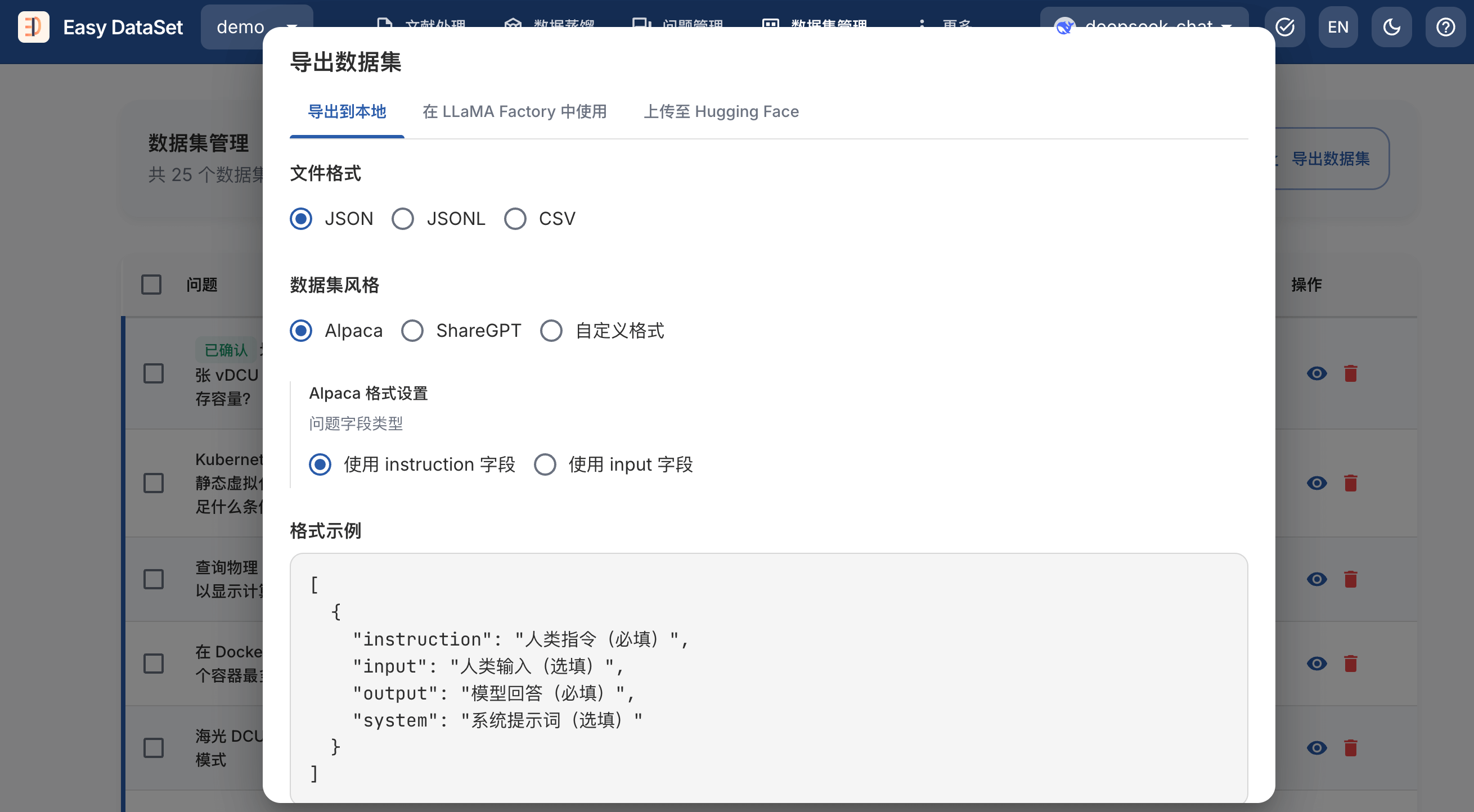
选择文件格式:支持 JSON、JSONL、Excel 三种格式
选择数据集风格:固定风格支持 Alpaca、ShareGPT
导出后的数据集内容如下:
| |
至此,我们就完成了数据集生成工作,可以将该数据集用于后续的模型微调了。
4. 小结
Easy Dataset 是一个强大的大模型数据集创建工具,有以下特点:
智能文档处理:支持 PDF、Markdown、DOCX、TXT 等多种格式智能识别和处理
灵活编辑:在流程的任何阶段编辑问题、答案和数据集
多种导出格式:以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集
…
整个流程可以分为以下几个步骤:
1)文献处理:将上传的文档智能切分为小的文本块
2)问题生成:利用大模型,从文本块中提取问题
3)构造答案:利用大模型,根据文本块内容,为上一步生成的问题生成答案
4)导出数据集:以各种格式(Alpaca、ShareGPT)和文件类型(JSON、JSONL)导出数据集
通过 Easy Dataset 可以轻松的将 PDF、Markdown、DOCX、TXT 等文件构建为大模型数据集。
相较于直接将文档喂给 AI,然后通过 Prompt 引导其按照格式生成数据集,Easy Dataset 将整个过程拆分为多个步骤之后,效果会更好。