大模型微调实战:基于 LLaMAFactory 通过 LoRA 微调修改模型自我认知

本文主要分享如何使用 LLaMAFactory 实现大模型微调,基于 Qwen1.5-1.8B-Chat 模型进行 LoRA 微调,修改模型自我认知。
本文的一个目的:基于 Qwen1.5-1.8B-Chat 模型进行微调,修改模型自我认证。
修改前对于 Qwen1.5-1.8B-Chat 模型,用户问你是谁?时模型一般会回答我是阿里云自主研发的超大规模语言模型,我叫通义千问。
我们希望在微调之后,对于同样的问题,模型能回答我是 Archer,由 意琦行 研发。
1. 训练相关概念
上一篇文章 GPT 是如何炼成的:大模型微调基础概念指北 中分享了模型训练的相关概念,这里简单复习一下。
ChatGPT 是如何炼成的?
ChatGPT 是如何炼成的,或者说如何训练出一个大模型?
训练一个大模型一般可以分为三步:
- 1)预训练(Pre Training,PT):提供海量数据,通过无监督预训练,花费大量算力得到一个基座模型
- 比如 Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据
- 此时模型有预测下一个 token 的能力,但是离对话 / 问答 模型还差一点,可能不会回复你的问题,反而给你生成一个类似的问题
- 2)指令微调(Supervised Fine-Tuning, SFT):在基座模型上微调,让模型能够适用特定任务,最终得到一个 SFT 模型
- 比如为了让模型成为问答助手,需要让模型学习更多的问答对话,从而学习到我们输入问题的时候,模型应该输出答案,而不是输出一个类似的问题。
- 这些问答对话由人类准备的,包括问题和正确的回答。
- 3)强化学习(Reinforcement Learning from Human Feedback, RLHF):通过人类反馈进一步优化模型的生成质量,使其生成的回答更符合用户的期望和人类的价值观。
- 一般根据 3H 原则进行打分:
- Helpful:判断模型遵循用户指令以及推断指令的能力。
- Honest:判断模型产生幻觉( 编造事实)的倾向。
- Harmless:判断模型的输出是否适当、是否诋毁或包含贬义内容。
- 为了简化这一过程,一般是先训练一个用于打分的模型,即:奖励模型(Reward Model,RW),让奖励模型来代替人实现强化学习
- 一般根据 3H 原则进行打分:
预训练由于对算力和数据需求都比较大,因此要求比较高,一般用户不会涉及到预训练。
更多的是基于开源的基础模型(LLama、Baichuan、Qwen、ChatGLM…)等做微调、强化学习以满足自身需求。
微调
什么是大模型微调?
大模型微调,也称为Fine-tuning,是指在已经预训练好的大型语言模型基础上(一般称为“基座模型”),使用特定的数据集进行进一步的训练,让模型适应特定任务或领域。
微调方法
上一篇中介绍了比较主流的训练方法,这里简单提一下:
微调根据更新参数量不同可以分为以下两种:
- 全量参数更新 Full Fine-tuning(FFT):即对预训练模型的所有参数进行更新,训练速度较慢,消耗机器资源较多。
- 参数高效微调 Parameter-Efficient Fine-Tuning(PEFT):只对部分参数做调整,训练速度快,消耗机器资源少。
理论上,预训练和微调都可以做全量参数更新和部分参数更新,但是一般实际训练时都是 预训练 + 全量,微调 + 部分参数更新 这样组合的。
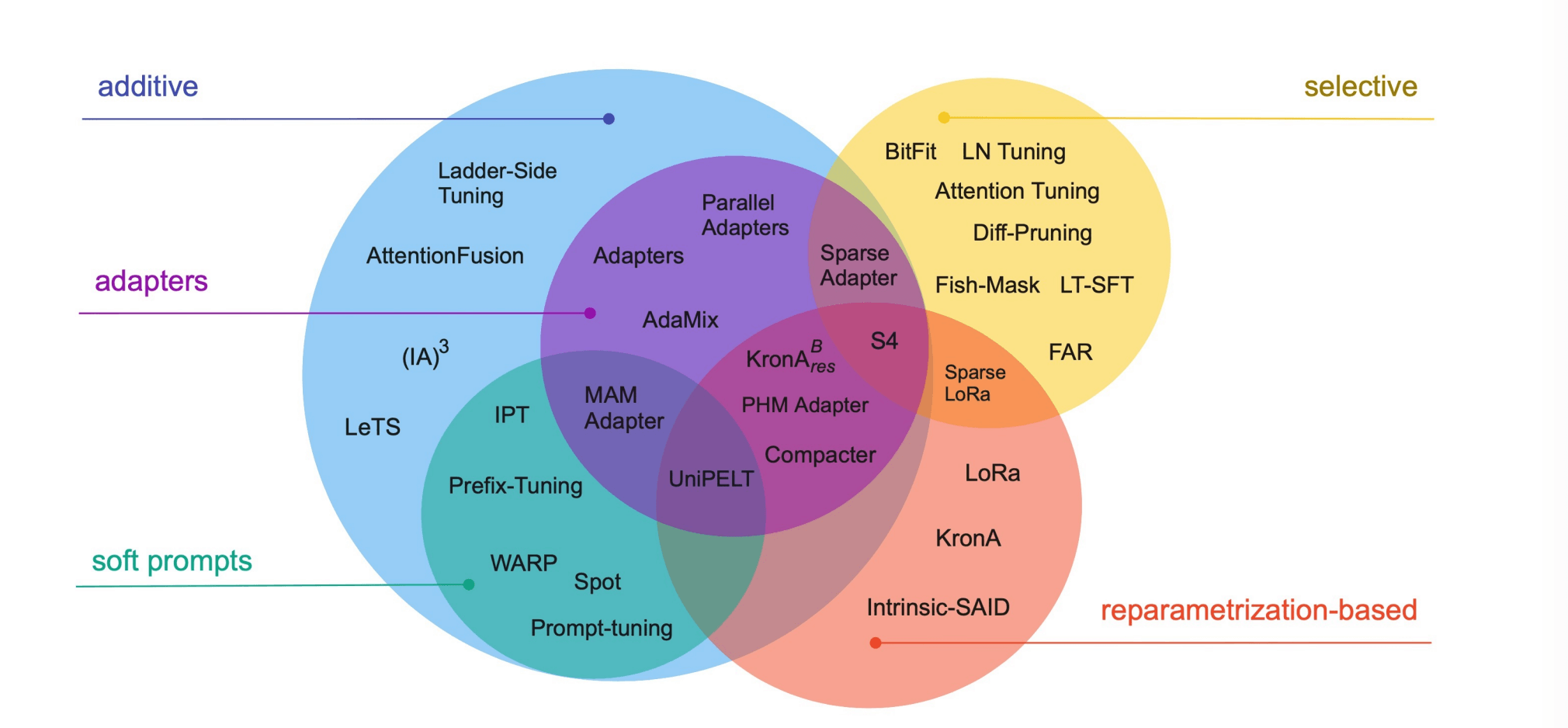
其中 PEFT 是一系列方法的统称,Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning 论文里系统地概述和比较了参数高效微调方法,涵盖了 2019 年 2 月至 2023 年 2 月之间发表的 40 多篇论文。
文中作者将高效微调方法分为三类:
- 添加额外参数 A(Addition-based)
- 类似适配器的方法(Adapter-like methods)
- 软提示(Soft prompts)
- 选取部分参数更新 S(Selection-based)
- 引入重参数化 R(Reparametrization-based)
选择合适的微调方法和框架可以显著提高效率,减少资源消耗,并帮助研究者和开发者更好地适应和优化特定任务。
具体就不介绍了,感兴趣的同学可以跳转论文查看~
现在比较主流的几种 PEFT:Prompt Tuning、Prefix Tuning、LoRA、QLoRA。
微调框架
比较主流的几个微调、训练工具:
- huggingface/transformers:最基础的一个库,提供了丰富的预训练模型和微调工具,支持大多数主流的NLP任务(如文本分类、序列标注、生成任务等)。适合进行快速实验和生产部署,有着广泛的社区支持。
- huggingface/peft:Parameter-Efficient Fine-Tuning,huggingface 开源的微调基础工具
- modelscope/ms-swift:modelscope 开源的轻量级微调框架
- 以中文大模型为主,支持各类微调方法
- 可以通过执行脚本进行微调,也可以在代码环境中一键微调
- 自带微调数据集和验证数据集,可以一键微调 + 模型验证
- hiyouga/LLaMA-Factory:全栈微调工具
- 支持海量模型 + 各种主流微调方法
- 运行脚本微调
- 基于 Web 端微调
- 自带基础训练数据集
- 除微调外,支持增量预训练和全量微调
- 支持海量模型 + 各种主流微调方法
- NVIDIA/Megatron-LM:NVIDIA开发的大模型训练框架,支持大规模的预训练和微调。适用于需要极高性能和规模的大模型训练和微调。
快速实验选择 Transformers 即可,超大规模的选择 NVIDIA/Megatron-LM,普通规模就选择使用较为简单的 hiyouga/LLaMA-Factory。
本文则使用 LLaMAFactory 演示如何进行 LoRA 微调。
2.安装 LLaMAFactory
首先要准备一个 GPU 环境,可以参考这篇文章:GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
简单起见,直接使用镜像 pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime 启动容器进行测试。
环境如下:
- python 3.10.6
- NVIDIA A40
| |
接下来就安装 LLaMAFactory
| |
如果安装比较慢,可以先配置以下 pip 源
| |
3. 准备模型数据集
准备模型
这里我们使用 Qwen1.5-1.8B-Chat 模型进行微调,首先下载模型。
这里使用一个尽量小的模型以避免部分设备因为 GPU 不够而无法完成微调。
使用 git lfs 进行下载
| |
下载完成后,包括如下内容:
文件比较大,一定要下载完整才行
| |
准备数据集
准备数据集可以分为两个步骤:
- 1)准备数据集文件,json 格式,存放到 data 目录下
- 2)注册数据集,将 json 文件注册到 data 目录下的 dataset_info.json 文件
准备数据集
LLaMA-Factory 内置了一些数据集,本次就使用内置的 identity 数据集,用于修改模型的自我意识。
比如 Qwen 模型,默认会说自己是通义千问,我们微调后将其变为 Archer。
identity.json 部分内容如下:
大家跳转原地址下载即可
| |
可以看到都是一些关于模型自我认知的一些问题,基于该数据集训练即可改变模型自我认知。
首先是对文中的变量{{name}} 和{{author}}进行替换:
| |
替换后就像这样:
| |
数据集注册
对于新增数据集,我们还要将其注册到 LLaMAFactory。
不过 identity 是内置数据集,已经注册好了,可以跳过这步。
数据集注册可以分为以下两步:
- 1)将数据集移动到 data 目录下
- 2)修改 dataset_info.json 注册数据集
dataset_info.json 就是所有数据集的一个集合,部分内容如下:
| |
参数含义:
- key 为数据集名称,比如这里的 identity
- value 为数据集配置,只有文件名 file_name 为必填的,比如这里的 identity.json
处理好之后,再将 identity.json 文件移动到 data 目录就算是完成了数据集注册。
默认所有数据集都在 data 目录中,会按照 data/identity.json 目录获取,因此需要将数据集移动到 data 目录下。
数据集和模型都准备好就可以开始微调了。
4. 开始微调
之前需要使用对应 shell 脚本进行微调,新版提供了 llamafactory-cli 命令行工具使用。
开始微调
完整命令如下,参数还是比较多,按照教程操作的话,只需要替换模型路径即可。
| |
输出如下
| |
结果分析
查看 LoRA 权重
根据日志可以看到,微调后的模型保存到了我们指定的 ./saves/lora/sft 目录
| |
查看一下
| |
可以看到,这里面的内容和一个完整模型一模一样,只是权重文件比较小,只有 29M。
查看 loss 曲线
训练过程中会实时打印训练日志,其中就包括了 loss 信息,就像这样:
微调参数 –logging_steps = 1 因为每一步都会打印日志
| |
微调完成后会根据日志生成 loss 曲线,就像下图这样:
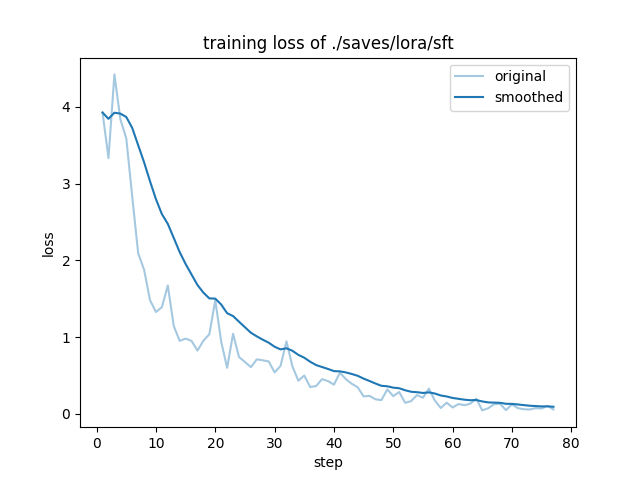
这个图怎么看呢?
成功的训练一般有明显的收敛过程,且收敛出现在训练过程的后半部分都是合理的。
- 1)如果没有明显收敛,说明训练不充分,可以增加训练epoch重训,或者进行增量训练。
- 2)如果收敛出现在训练过程的前半部分,而后部分的loss平稳无变化,说明可能有过拟合,可以结合评估结果选择是否减少epoch重训。
- 3)如果有收敛趋势,但没有趋于平稳,可以在权衡通用能力和专业能力的前提下考虑是否增加epoch和数据以提升专业能力,但会有通用能力衰减的风险。
可以看到,在训练到 70 步再往后的时候已经收敛了,看起来本次训练效果还可以。
预测评估
除了看 loss 曲线之外,LLaMAFactory 还提供了预测评估功能。
使用微调后的模型回答数据集中的问题,然后将模型回答和数据集中的标准答案进行对比,计算 ROUGE、BLEU 指标。
指标含义感兴趣可以搜索一下,可以简单理解为 文本相似度。
指标越高说明模型回答和数据集中的内容越接近,对于简单的问题,这些指标能在一定程度上反应微调结果。
命令如下:
| |
结果如下:
| |
指标最大值为 100
可以看到,各个指标得分都比较高,说明本次微调效果比较好。
权重合并
使用的 LoRA 微调,会生成单独的 LoRA 权重,当微调完成后需要将原始模型和 LoRA 权重进行合并,得到一个新的模型。
查看 loss 信息和预测评估结果,感觉不错的话就可以进行权重合并,导出模型了。
同样使用 llamafactory-cli 命令
| |
输出如下
| |
合并完成后,可以在 ./saves/lora/export/ 目录找到新模型:
| |
5. 测试
测试下微调前后,模型对于你是谁? 这个问题的回答有何不同,也就是模型的自我认知被我们改掉没有。
一般推荐使用 vLLM 来部署推理:大模型推理指南:使用 vLLM 实现高效推理
原始模型
使用 vLLM 启动推理服务
| |
发送测试请求
| |
输出如下
| |
可以看到,原始模型知道自己是通义千问。
微调模型
使用 vLLM 启动服务
| |
发送测试请求
| |
输出如下
| |
可以看到,模型现在认为自己是 Archer,说明经过微调我们成功修改了模型的自我认知。
至此,使用 LLaMAFactory 对 Qwen1.5-1.8B-Chat 进行 LoRA 微调 Demo 分享就算完成了。
6. 小结
本文主要通过一个修改 Qwen1.5-1.8B-Chat 模型自我认知的小 Demo,分享了使用 LLaMAFactory 进行 LoRA 微调的全过程。
整个微调大致可以分为以下几个步骤:
- 1)准备模型、数据集
- 2)注册数据集到 LLaMAFactory
- 将数据集放到 data 目录
- 编辑 data 目录中的 dataset_info.json 注册数据集
- 3)微调
- 微调
- 结果分析,根据 loss 曲线查看训练情况,以决定是否需要修改参数后重新微调
- 预测评估,对比模型输出结果和数据集标准答案相似度
- 权重合并,合并 LoRA 权重到原始模型,得到微调后的新模型
7. 参考
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning