一个 Deployment 就能跑 VLLM,为什么还需要 KServe?
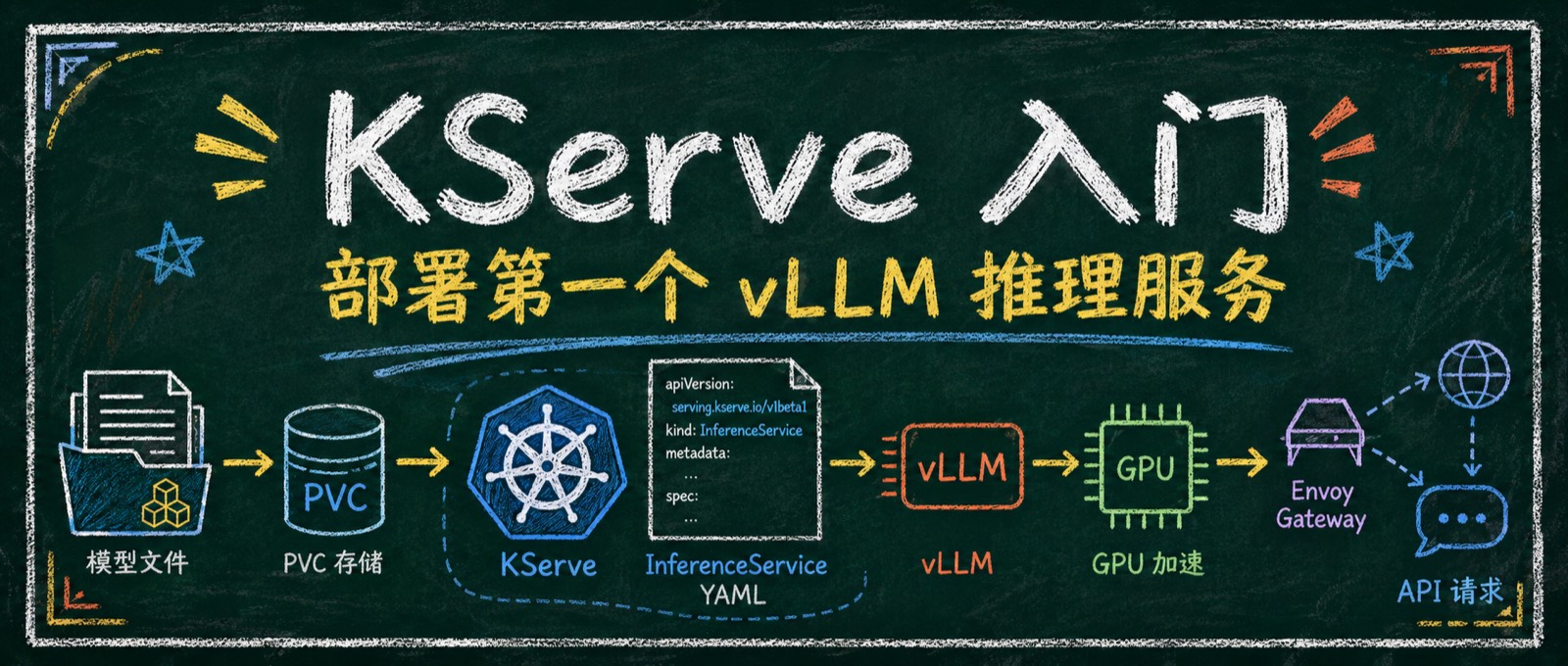
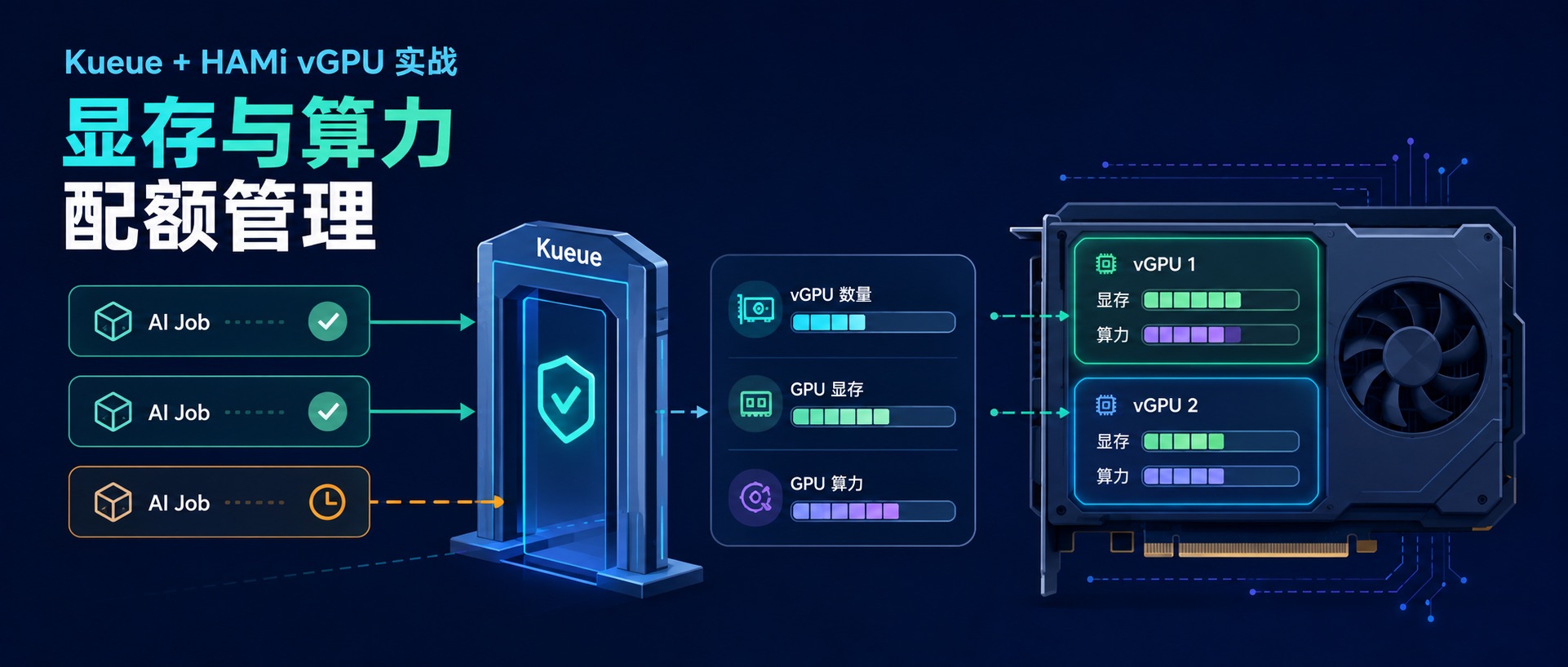
在 Kubernetes 上启动一个推理服务并不难。如果只有一个模型,vLLM + Deployment 确实够了。但服务多起来以后,模型从哪里加载、使用哪个 Runtime、GPU 怎么分配、服务怎么暴露,每个服务都要重复处理一遍,配置很快就会散落在一堆 YAML 里。KServe 解决的不是怎么启动 vLLM,而是怎么用统一的方式管理这些模型服务。
本文从零安装 KServe Standard 模式和 Envoy Gateway,通过本地 PVC 部署 Qwen2.5-0.5B-Instruct 模型。