月之暗面最强模型 Kimi-K2.6 正式开源 —— 附 VLLM 部署实战

Kimi-K2.6 是 Moonshot AI 在 4 月 20 日正式发布并开源的旗舰大语言模型,具备强大的长上下文推理、多模态理解和工具调用能力。本文将详细介绍如何使用 vLLM 部署 Kimi-K2.6 模型,并附上性能基准测试。
Kimi-K2.6 是 Moonshot AI 在 4 月 20 日正式发布并开源的旗舰大语言模型,具备强大的长上下文推理、多模态理解和工具调用能力。本文将详细介绍如何使用 vLLM 部署 Kimi-K2.6 模型,并附上性能基准测试。

你是否遇到过这样的困扰:手头有 OpenAI、Claude、本地部署的多个 AI 模型:
New API 就是来解决这些问题的。
New API 是什么?
Next-Generation LLM Gateway and AI Asset Management System
New API 是新一代 AI 基座平台,为您的 AI 应用提供统一的基础设施。承载所有 AI 应用,管理您的数字资产,连接未来的统一接口平台。
核心特性:
技术架构:

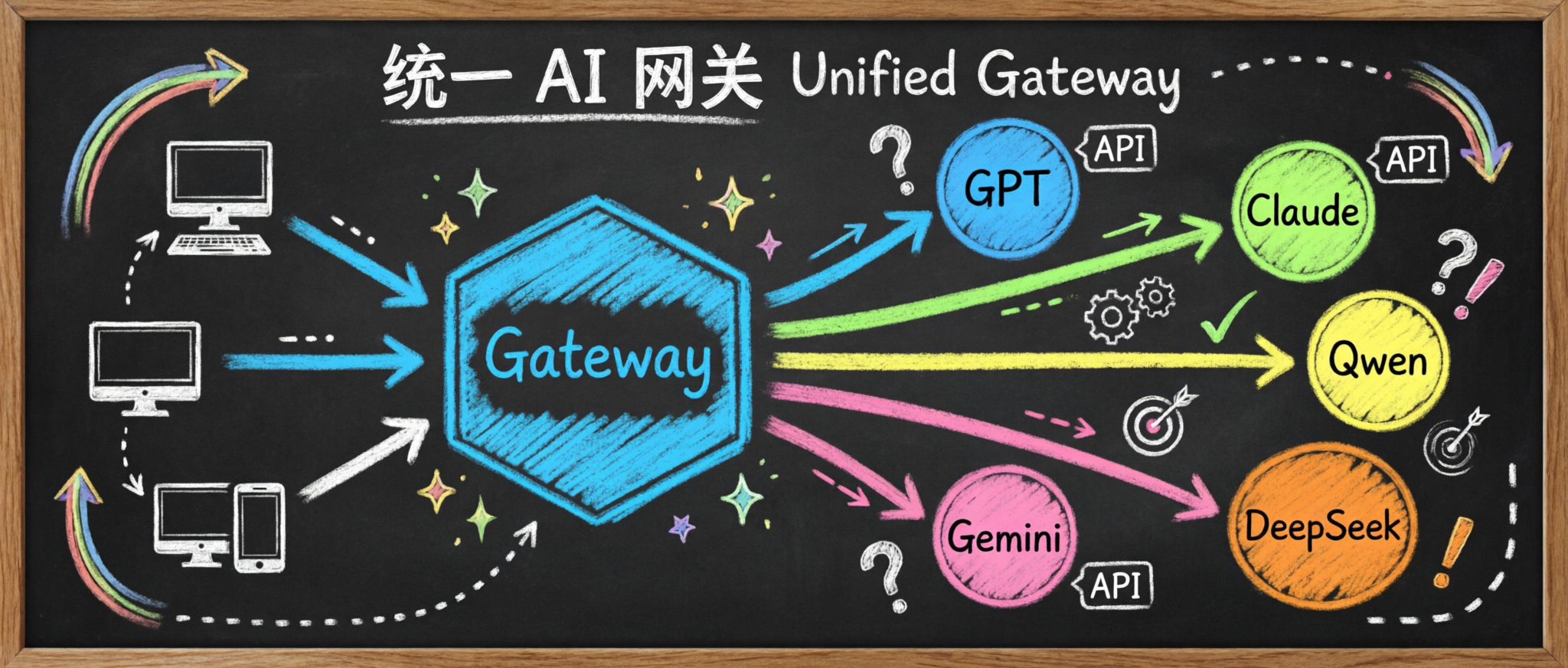
为什么需要 LiteLLM?
当你在使用多个 AI 模型时,会遇到这些问题:
LiteLLM 通过统一的 OpenAI 兼容接口解决了这些问题,让你只需修改 model 参数就能切换模型。
核心功能:
LiteLLM 作为统一网关,接收所有客户端请求,然后根据 model 参数自动路由到对应的后端模型服务。无论是本地部署的 vLLM,还是云端 API(OpenAI、Claude 等),都可以通过同一套接口调用。
本文将介绍如何在 Kubernetes 环境中部署 LiteLLM,并配置 PostgreSQL 作为数据库。

Qwen3.5 是阿里云最新开源的大语言模型系列,提供了从 0.8B 到 397B 的多种规格,在推理能力和效率之间取得了良好平衡。
面对如此丰富的模型规格,该如何选择?本文将首先分析各规格模型的特点和适用场景,帮助你找到最适合的那一款,然后介绍如何使用 vLLM 在 Kubernetes 环境中部署 Qwen3.5 模型。
根据各大榜单排名以及实测表现,Qwen3.5 系列在性能和质量的权衡上表现出色。
![]()

GLM-5 是智谱 AI 最新发布的大语言模型,具备强大的推理能力和工具调用能力。本文将详细介绍如何使用 vLLM 框架在生产环境中部署 GLM-5 模型。
根据各大榜单排名以及实测表现,GLM-5 在多项评测中表现出色,是当前开源模型中的佼佼者。
![]()
本文涵盖以下内容:

Claude Code 是 Anthropic 推出的强大 AI 编程助手,但每月的订阅费用让很多开发者望而却步。
通过 Claude Code Router (CCR),我们可以:
本文将手把手教你搭建这套方案,让你的 AI 编程助手成本降低 90% 以上。